SwinTrack: A Simple and Strong Baseline for Transformer Tracking
Liting Lin1,2∗ Heng Fan3∗ Zhipeng Zhang4 Yong Xu1,2 Haibin Ling5
SwinTrack: A Simple and Strong Baseline for Transformer Tracking
Recently Transformer has been largely explored in tracking and shown state-of-the-art (SOTA) performance. However, existing efforts mainly focus on fusing and enhancing features generated by convolutional neural networks (CNNs). The potential of Transforme
arxiv.org
Abstract
- 최근 트랜스포머는 tracking에서 크게 탐구되었고, 최첨단(SOTA_state-of-the-art) 성능을 보여주었다.
- 그러나 기존의 노력은 주로 컨볼루션 신경망(CNN)에 의해 생성된 feature을 융합하고 향상시키는 데 초점을 맞추고 있다.
- representation learning에서 트랜스포머의 잠재력은 아직 충분히 탐구되지 않았다.
- 본 논문에서는 고전적인 Siamese framework 내에서 SwinTrack이라고 하는 간단하면서도 효율적인 fully-attentional tracker를 제안하여 트랜스포머의 힘을 더욱 발휘하는 것을 목표로 한다.
- 특히 SwinTrack의 representation learning and feature fusion은 모두 트랜스포머 아키텍쳐를 활용하여 pure CNN or hybrid CNN-Transformer frameworks보다 tracking에 더 나은 feature interaction을 가능하게 한다.
- 또한 robustness를 더욱 향상시키기 위해, temporal context를 제공하여 추적을 개선하기 위해 historical target trajectory를 포함하는 새로운 motion token을 제시한다.
- trajectory : 순차적으로 정렬된 좌표 목록으로 구성되며, 시간 처리를 의미
- motion token은 무시할 수 있는 계산으로 가볍지만 분명한 이득을 가져온다.
- 철저한 실험에서 SwinTrack은 여러 벤치마크에서 기존의 접근 방식을 능가한다.
- 특히 어려운 LaSOT에서 SwinTrack은 0.713이라는 SUC score로 신기록을 세웠다.
- 또한 다른 벤치마크에서 SOTA 결과를 달성한다.
- SwinTrack이 트랜스포머 tracking을 위해 견고한 baseline 역할을 하고 향후 연구를 용이하게 할 것으로 기대한다.
Introduction
VOT에서 Transformer
- 시각적 추적은 딥러닝 이후 상당한 진전을 보였다.
- 특히 최근의 Transformer[38]은 long-range dependencies을 모델링하는 능력으로 인해 추적에서 최첨단 기술을 크게 발전시켰다.
- 그러나 기존 방법은 일반적으로 ResNet[18]과 같은 합성곱 신경망(CNN)에서 생성된 feature을 융합하고 강화하기 위해 Transformer를 활용한다.
- Feature representation learning을 위해 Transformer를 활용할 수 있는 잠재력은 대체로 충분히 탐구되지 않았다.
Transformer의 발전 및 본 논문의 키워드
-
- 이에서 영감을 얻어 본 논문에서는 feature fusion 외에도 추적에서의 representation learning이 attention을 통해 트랜스포머의 이점을 얻을 수 있다고 주장한다.
- 따라서 Siamese 아키텍쳐를 기반으로 한 fully attentional tracking framework를 개발할 것을 제안한다.
- 특히 feature representation learning과 template and search region의 feature fusion은 모두 Transformer에 의해 실현된다.
- 보다 구체적으로 강력한 Swin Transformer[28]의 아키텍쳐를 빌려 Siamese tracking에 적용한다.
- 다른 트랜스포머 아키텍쳐를 사용할 수 있다.
- feature fusion을 위해 query-based decoder 없는, 간단한 homogeneous concatenation-based fusion 아키텍쳐를 도입한다.
- 또한 tracking이 시간적 작업이라는 점을 고려하여 robustness를 향상시키기 위해 새로운 motion token을 제안한다.
- target이 보통 짧은 시간 내에 부드럽게 이동한다는 데에서 영감을 받아, motion token은 local temporal window 내에서 historical target trajectory로 표현된다.
- 추적하는 동안 motion information을 활용하기 위해, (single) motion token을 feature fusion의 decoder에 통합한다.
- 개념적으로 간단하지만 본 논문의 motioin token은 무시할 수 있는 계산으로 추적 성능을 효과적으로 향상시킬 수 있다.최근 ViT[9]는 강력한 feature representation learning에서 큰 잠재력을 보여주었다.
- 특히 extension Swin Transformer[28]는 여러 작업에서 최첨단(SOTA) 결과를 달성했다.
- 이에서 영감을 얻어 본 논문에서는 feature fusion 외에도 추적에서의 representation learning이 attention을 통해 트랜스포머의 이점을 얻을 수 있다고 주장한다.
간단한 결과 및 기여

- 본 논문의 프레임워크에 SwinTrack이라는 이름을 붙인다.
- pure Transformer framework인 SwinTrack은 pure CNN 기반[1, 25] 및 hybrid CNN-Transformer[5, 40, 46] 프레임워크에 비해 template/search region의 feature learning과, 그들의 융합 내부에서 더 나은 상호 작용을 가능하게 하여 더 강력한 성능을 제공한다.(그림 1 참고)
- 그림 2는 SwinTrack의 아키텍쳐를 보여준다.
- LaSOT, LaSOT_ext, TrackingNet, GOT-10k, TNL2K를 포함한 5개의 대규모 벤치마크에 대한 광범위한 실험을 수행한다.
- 모든 벤치마크에서 SwinTrack은 유망한 결과를 달성하는 한편, 45fps로 빠르게 실행된다.
- 특히 어려운 LaSOT에서 SwinTrack은 71.3 SUC score라는 새로운 기록을 세우며, 이전의 가장 강력한 추적기[46]을 3.1% 높고, 0.7 SUC 임계값을 처음으로 넘어섰다.
- 다른 벤치마크에서도 SOTA보다 낫거나 동등한 결과를 보인다.
- 또한 SOTA와 유사한 결과를 얻지만 약 98fps에서 훨씬 더 빠르게 실행되는 가벼운 버전의 SwinTrack을 제공한다.
- 본 논문의 기여는 다음과 같다.
1️⃣ Fully attentional tracking을 위한 간단하고 강력한 baseline인 SwinTrack을 제안한다.
2️⃣ tracking 동안 풍부한 motion context의 integration을 가능하게 하는, 간단하면서도 효과적인 motion token을 제시하며, 이것은 무시할 수 있는 계산으로 SwinTrack의 견고성을 더욱 향상시킨다.
3️⃣ 제안된 SwinTrack은 여러 벤치마크에서 최첨단 성능을 달성한다.
4️⃣ SwinTrack이 Transformer의 잠재력을 더욱 보여줄 것으로 믿고 있으며, 향후 연구의 기준이 될 것으로 기대한다.
Related Work
Siamese Tracking
- Siamese tracking 방법의 목표
- tracking을 matching 문제로 공식화하고,
- 이 작업에 위해 generic matching function을 offline에서 학습하는 것
- 종류
- [1]의 주요 방법은 추적을 위해 fully convolutional Siamese network를 도입하고, accuracy와 speed 사이의 좋은 균형을 보여준다.
- scale variation을 처리하는 데 있어서 Siamese tracking을 개선하기 위해 [25]의 작업은 region proposal network(RPN)[34]를 Siamese network에 통합하고 anchor-based 추적기를 제안하여 더 빠른 속도로 더 높은 정확도를 보여준다.
- 나중에, deeper backbone[24], multi-stage architecture[12, 13], anchor-free Siamese trackers[52], deformable attention[48]을 포함하여 Siamese tracking을 개선하기 위한 수많은 확장이 제시되었다.
Transformer in Vision
- Transformer[38]은 기계 번역을 위한 자연어 처리(NLP)에서 유래했으며 최근 비전에 도입되어 큰 잠재력을 보여준다.
- [3]의 작업은 먼저 Object detection을 위해 transformer을 사용하고 유망한 결과를 달성했다.
- representation learning에서 transformer의 능력을 탐구하기 위해
- [9]의 작업은 transformer를 적용하여 backbone network를 구성하고, 그 결과인 ViT는 컨볼루션 네트워크에 비해 우수한 성능을 달성하는 동시에 더 적은 훈련 리소스를 요구하므로 ViT에 대한 많은 확장을 장려한다.[37, 4, 49, 41, 28]
- 그 중에서도 SiwnTransformer[28]는 많은 관심을 받았다.
- ViT의 fixed-patch method를 대체하기 위해
- simple shifted window 전략을 제안
- 이는 효율성을 크게 향상시키는 동시에 여러 이미지 작업에 대한 최첨단 결과를 보여준다.
- 본 논문의 작업은 Swin Transformer에서 영감을 얻었지만, 시각적 추적의 비디오 작업에 초점을 맞춘다.
Transformer in Tracking
- 다른 분야에서의 성공에 영감을 받은 연구원들은 tracking을 위해 Transformer를 활용했다.
- [5]의 방법은 개선을 위해 Siamese tracking의 features을 강화하고 융합하기 위해 Transformer를 적용한다.
- [40]의 접근 방식은 Transformer를 사용하여 temporal features를 활용하여 tracking robustness를 향상시킨다.
- [46]의 작업은 시각적 추적 전용의 새로운 Transformer 아키텍쳐를 소개하고, 모델 업데이트 작업을 Transformer module에 통합하여 Spatio-temporal Transformer를 탐색한다.
- 본 논문의 SwinTrack은 Transformer 기반 추적기와 관련이 있지만 크게 다르다.
- 구체적으로, 앞서 언급한 방법은 주로 Transformer를 fuse convolutional features에 적용하고, hybrid CNN-Transformer 아키텍쳐에 속한다.
- 이들과 달리 SwinTrack은 representation learning과 feature fusion이 Transformer로 실현되는 pure Transformer 기반 추적 아키텍쳐로, 강력한 추적을 위해 더 나은 features를 탐색할 수 있다.
Tracking via Vision-Motion Transformer

- 그림 2에서 object tracking을 위한 a vision-motion integrated Transformer인 SwinTrack을 제시한다.
- 제안된 프레임워크는 세가지 주요 구성 요소를 포함한다.
-
더보기
- ① feature extraction을 위한 Swin-Transformer backbone
- ② vision-motion cues를 mixing하기 위한 encoder-decoder network
- ③ target을 localizing하기 위한 head network를 포함한다.
- 다음 섹션에서는
-
더보기
- 먼저 Swin backbone network를 간략하게 설명한 다음,
- 제안된 vision motion encoder-decoder에 대해 자세히 설명한다.
- 그 후, 본 논문의 방법에 대해 논의하고, network head & training loss에 대해 간략하게 설명한다.
Swin-Transformer for Feature Extraction
- deep convolutional neural network는 추적기의 성능을 크게 향상시켰다.
- 추적기의 발전과 함께, backbone network는 두번 발전했다.
- AlexNet[22] 및 ResNet[18]
- Swin-Transformer[28]
- ResNet과 비교하여 보다 compact feature representation and richer semantic information를 제공
- 후속 네트워크에 target object를 더 잘 localizing 할 수 있도록 지원할 수 있으며(절제 연구에서 입증됨),
- 따라서 모델의 basic feature extraction을 위해 선택된다.
- Siamese tracking framework[1]를 따라, 본 논문의 추적기는 Input으로 한 쌍의 이미지 패치를 필요로 한다.
- 즉, template image and search region image
- 일반적인 Swin Transformer 절차와 마찬가지로,
- template and search region images는 중복되지 않은 패치로 분할되어 네트워크에 전송되며,
- 이는 template tokens and search region tokens을 생성
- s는 backbone network의 stride
- 본 모델에는 dimension projection이 없기 때문에 C는 전체 모델의 hidden dimension이다.
Vision-Motion Representation Learning
- Matching-based visual tracking을 위한 필수 단계는 search region에 template 정보를 주입하는 것이다.
- 인코더를 채택하여 template과 search region의 feature을 융합하는 한편,
- 디코더는 그림2와 같이 vision-motion representation learning을 달성하도록 배열된다.
1) Encoder for fusing template and search tokens
- 인코더의 구성 (일련의 Transformer block)
- MSA module(multi-head self-attention)
- FFN(feed-forward network)
- two-layers MLP(multi-layer perceptron)을 포함
- GELU activation layer는 first linear layer 이후에 삽입
- LN(layer normalization)은 항상 모든 module(MSA, FFN)보다 먼저 수행된다.
- Residual connection은 MSA, FFN modules에 적용된다.
- 인코더의 과정
- 먼저 인코더에 features를 공급하기 전에 template and search region tokens은 spatial dimensions를 따라 연결되어 mixing representation f_m을 생성한다.
- 각 블록에 대해 MSA module은 mixing union representation에 대한 self-attention을 계산
- 이는 T-token/S-token에 대한 self-attention을 별도로 수행하는 동시에, T-token과 S-token 간의 cross-attention을 수행하는 것과 같으나 더 효율적이다.
- FFN은 MSA에 의해 생성된 features을 refine한다.
- 토큰이 인코더에서 빠져나오면 template과 search region token을 분리하기 위해, de-concatenation operation이 준비된다.
- 인코더의 과정은 다음과 같이 표현할 수 있다.

2) Decoder for fusing vision and motion information
- 디코더의 아키텍쳐를 설명하기 전에 알아야 할 것
💡 Motion token 생성하는 방법
- motion token은 target object의 historical trajectory의 embedding이다.
- past object trajectory는 target object box 좌표의 집합으로 표현되며, T = {oo_1, oo_2, ..., oo_t}
- 여기서 t는 frame index
- o는 target object의 bounding box로써, target object의 top-left and bottom-right corners로 정의된다. oo_t = (o_t^x1, o_t^y1, o_t^x2, o_t^y2)
💡 Sampling Process(for flexible modeling)
1) Fixed length
2) Focusing on the latest trajectories
3) Reducing redundancy
- 1️⃣ 본 논문의 방법에서 다음과 같이 object trajectory를 샘플링한다.

- 2️⃣ Point 변형(Siamese tracker의 경우, search region은 input image로부터 잘린다.)
- 상세하게는, resizing operation이 있는 cropping을 사용하여 과정을 설명할 수 있다.
- input image의 point를 (x_i, y_i)로, search search의 해당 point를 (x_o, y_o)로 지정하면,
- Siamese Tracker의 pre-processing에 사용되는 cropping process를 x_o and y_o로 공식화 할 수 있다.
- (i_x, i_y) : input image에서 cropping window의 중심
- (s_x, s_y) : scaling factor
- (o_x, o_y) : search region에서 cropped and scaled window의 중심
- Object trajectory을 cropping에 대해 invariant로 만들기 위해, sampled object trajectory에 동일한 변환을 적용

- 3️⃣ 그런 다음, 변환된 object trajectory를 네트워크에 embed하기 위해,
- 4개의 embedding matrices를 채택하여 elements를 박스 좌표에 각각 embed.
- embedding matrix를 W로 나타낸다.
- 4개의 embedding matrices를 채택하여 elements를 박스 좌표에 각각 embed.

-
- embedding matrix의 last entry는 padding vector로 사용되며, object absence or out of the search region과 같은 잘못된 상태를 나타낸다.
- 따라서 [1, g]의 범위에서 샘플링된 target object 상자 좌표를 정규화하고, 임베딩 벡터의 인덱스를 얻기 위해 정수로 quantize한다.

- 4️⃣ Motion token E_motion
- Sampled object trajectory의 모든 상자 좌표 임베딩의 concatenation에 의해 제공된다.
- Motion token의 구성은 embedding lookups and token concatenation의 구성 뿐이기 때문에 FLOPs는 무시할 수 있다.

- 디코더의 구성
- MCA(multi-head cross-attention)
- FFN(feed-forward network)
- 디코더의 과정
- 디코더는 인코더와 motion token의 출력을 입력으로 가져와 f_x^L and Concat(E_motion, f_z^L, f_x^L)에 대한 cross-attention을 계산하여 final vision-motion representation f_vm을 생성한다.
- 디코더는 마지막 layer에서 template image로부터 feature를 업데이트할 필요가 없기 때문에, template token과 search token 간의 correlation이 떨어진다는 점을 제외하고는 인코더의 layer와 유사하다.
- 디코더의 과정은 다음과 같이 공식화 된다.
- f_vm은 classification response map과 bounding box regression map을 생성하기 위해 head network에 feed할 것이다.

3) Positional Encoding
- self-attention module
- permutation-invariance이므로
- 트랜스포머는 current processing token[38]의 위치를 식별하기 위한 positional encoding을 필요로 한다.
- positional encoding method
- untied positional encoding[20]을 채택한다.
- untied positional encoding은 isolated positional embedding matrix를 가지고 token embeddings으로부터 positional embedding을 (untie)풀어서 모델의 표현력을 향상시킨다.
- 이것은 또한 본 논문의 motion token과 같은 특수한 토큰의 경우도 고려한다.
- untied positional encoding[20]을 채택한다.
- 추적기에서 concatenated-based fusion을 준수하기 위해 untied positional encoding을 multi-dimensions multi-sources data로 일반화한다.
- 자세한 내용은 부록 참고.
Discussion
1) Why concatenated attention ?
- 설명을 단순화하기 위해, 위에서 설명한 방법은 concatenation-based fusion이라고 부른다.
- 아래의 방법은 cross-attention-based fusion이라고 부른다.
- multiple sources로부터 feature을 fuse and process하려면,
- 각 source의 feature에 대해 개별적으로 self-attention을 수행한 다음,
- 다른 sources의 feature에 대한 cross-attention을 계산하는 것이 직관적이다.
- 트랜스포머는 데이터의 spatial structure에 대한 가정을 적게 하므로 모델링 유연성이 뛰어나다.
- cross-attention-based fusion과 비교하여, concatenation-based fusion은
- operation sharing을 통해 계산 비용을 절약하고,
- weight sharing을 통해 모델 파라미터를 줄일 수 있다.
- metric learning의 관점에서, weight sharing은 데이터의 two branches 사이의 metric이 대칭인지 확인하기 위한 필수 설계이다.
- concatenation-based fusion을 통해, feature extraction 단계 뿐만 아니라 feature fusion 단계에서도 이 특성을 구현한다.
- 일반적으로 concatenation-based fusion은 효율성과 성능을 모두 향상시킨다.
2) Why not window-based selft/cross - attention ?
- Siwn-Transformer의 output으로 stage 3을 선택하기 때문에, 관련된 토큰 수가 크게 감소하므로, window-based attention은 너무 많은 FLOPs를 저장할 수 없다.
- 더욱이, window partition과 window reverse operation에 의해 도입된 추가 대기 시간을 고려할 때, window-based attention은 더 느릴 수 있다.
3) Why not a query-based decoder ?
- vanilla Transformer decoder에서 파생된 비전 작업의 많은 트랜스포머 기반 모델은 학습 가능한 쿼리를 활용하여 [3]에서 object queries, [46]에서 target query와 같이 인코더로부터 원하는 objective features를 추출한다.
- 그러나 본 논문의 실험에서 query-based decoder는 느린 수렴과 성능 저하로 어려움을 겪는다.
- 대부분의 Siamese trackers[25, 44, 16]은 추적을 전경/배경 분류로 공식화하여 배경 정보를 더 잘 활용할 수 있다.
- vanilla Transformer decoder는 generative model이며, generative approaches는 분류 작업에 적합하지 않은 것으로 간주된다.
- 다른 측면에서, 모든 종류의 object에 대한 일반적인 target query를 학습하는 것을 bottleneck을 일으킬 수 있다.
- vanilla transformer encoder-decoder 아키텍쳐 측면에서 SwinTrack은 "인코더" 전용 모델이다.
- 또한 response map에 Hanning penalty window를 사용하여 smooth movement assumption을 도입하는 것과 같이, classic Siamese tracker에 꽤 적은 도메인 지식을 쉽게 적용하여 성능을 향상시킬 수 있다.
- vanilla Transformer decoder는 generative model이며, generative approaches는 분류 작업에 적합하지 않은 것으로 간주된다.
4) Are other forms of motion token feasible ?
- motion token을 구성하기 위한 다른 형태들
- past box coordinate embeddings을 합산하여 구성
- 박스 당 하나의 토큰으로 past object trajectories를 표현
- 초기 실험에서, 제안된 motion token이 최고의 성능으로 더 효과적이라는 것을 발견했다.
- past box coordinate embeddings을 합산하면, 좌표 임베딩에 대한 과도한 매개 변수화를 초래할 수 있다.
- Multi-token 형태에서 single-layer decoder에 visual features와 함께 temporal motion representation을 추가하는 것은 효과적이지 않고, 이 형태에서는 정밀한 temporal modeling이 필요할 지도 모른다.
Head and Loss
1) Head
- Head network는 두개의 branches로 분할된다.
- classification and bounding box regression
- 그것들 각각은 three-layer perceptron이다.
- 둘 다 각각 classification response map r_cls 및 bounding box regression map r_reg을 예측하기 위해 input으로 디코터로부터의 feature map을 수신한다.

2) Classification Loss
- Training target : IoU-aware classification score(IACS) 사용
- Training loss function : varifocal loss[50] 사용
- IoU-aware design은 최근 매우 인기가 있지만 대부분의 연구는 IoU prediction을 classification or bounding box regression [52, 2, 44]를 지원하는 auxiliary branch로 간주한다.
- 서로 다른 prediction branches 사이의 gap을 제거하기 위해, [50], [26]은 ground-truth value로부터 hard classification target을 predicted bounding box and ground-truth 사이의 IoU로 대체하며, 이를 IoU-aware classification score(IACS)라고 한다.
- IACS은 모델이 더 정확한 bounding box prediction candidate를 선택하는 데 도움이 될 수 있다. (같은 위치에 또다른 branch에서 bounding box prediction의 quality를 예측함으로써 pool로부터)
- IACS을 따라, IACS 접근 방식이 다른 IoU-aware designs를 능가하도록 돕기 위해 [50]에서 varifocal loss가 제안되었다.
- classification loss는 다음과 같이 공식화 될 수 있다.

3) Regression Loss
- 일반화된 IoU loss[35]를 사용한다.
- regression loss function은 다음과 같이 공식화 될 수 있다.

-
- GIoU loss는 높은 분류 점수 샘플을 강조하기 위해 p로 가중된다.
- negative samples로부터 training signals은 무시된다.
Experiments
Implementation
1) Model
- 다음과 같이 구성이 다른 두가지 변형의 SwinTrack을 설계한다.
- 여기서 C와 N은 각각 SwinTransformer의 첫번째 단계에 있는 hidden layer의 channel number, feature fusion에 있는 인코더 블록의 수
- 모든 variants에서, feature extractioin을 위해 Swin Transformer의 third stage 이후의 output을 사용한다.
- 따라서 backbone stride s는 16이다.

- 구체적인 설정
- motion token의 경우, sampled object trajectory n의 개수는 16으로 설정되고, fixed sampling interval 세모은 15로 설정된다.
- 만약 video sequence의 frame rate이 가능하면, sampling interval은 frame rate에 따라 조정된다.
- rame rate이 f라고 가정하면, 새로운 sampling interval은 f*세모/30가 되며, 30fps는 본 논문에서 가정한 표준 frame rate이다.
- embedding granularity를 제어하는 g는 SiwmTrack-T-244의 경우 14, SwinTrack-B-384의 경우 24와 같이, search region feature map과 동일한 크기로 설정된다.
- GOT-10k sequence model의 경우, n=8, 세모=8로 설정되며, frame rate 조정이 적용되지 않는다.
2) Training
- LaSOT, TrackingNet, GOT-10k(공정한 비교를 위해 [46]에 따라 1000개의 비디오가 제거됨), COCO2017의 training splits를 사용하여 SwinTrack을 훈련한다.
- 또한 [19]에 설명된 프로토콜을 따라 training split만 있는 GOT-10k를 가지고 SwinTrack-T-224, SwinTrack-B-384의 결과를 보고한다.
- 이 모델은 AdamW[29]로 최적화되었으며, learning rate는 5e-4, weight decay는 1e-4이다.
- backbone의 learning rate는 5e-5로 설정된다.
- Epoch 당 131,072개의 샘플을 가지고, 300개의 epoch에 대해 8개의 NVIDIA V100 GPU에서 네트워크를 훈련시킨다.
- 210 에포크 이후 learning rate는 10배 감소한다.
- training 과정을 안정화하기 위해 3-epoch linear warmup이 적용된다.
- DropPath[23]은 0.1의 비율로 backbone과 encoder에 적용된다.
- GOT-10k 평가 프로토콜을 위해 훈련된 모델의 경우 과적합을 방지하기 위해, training epoch를 150으로 설정하고 120 epoch 이후 학습률을 떨어뜨린다.
- motion token의 경우, Siamese training pair에 대한 object trajectory는 위에서 설명한 방법으로 생성된다.
- object가 video sequence에 없는 것으로 주석을 단 프레임은 유효하지 않은 것으로 표시되고, 해당 box 좌표는 -무한으로 설정된다.
- 본 논문의 설정에서 coordinate embedding의 거친 세분성은 이미 과거 object trajectory의 augmentation으로 볼 수 있기 때문에 추가적인 data augmentation은 적용되지 않는다.
3) Inference
- 본 논문은 Siamese network-based tracking[1]에 대한 일반적인 절차를 따른다.
- template image는 video sequence의 첫번째 프레임에서 잘린다.
- target object는 2배의 background area를 가진 이미지의 중앙에 있다.
- search region은 current tracking frame에서 잘리며, image center는 이전 프레임에서 예측된 target center position이다.
- search region에 대한 background area factor : 4
- template image는 video sequence의 첫번째 프레임에서 잘린다.
- 본 논문의 SwinTrack은 template image와 search region을 inputs and output classification map and regression map으로 사용한다.
- 추적에 앞서, positional을 활용하기 위해, r_cls에 hanning window penalty를 적용하고, 최종 classification map r'_cls는 (1-r) x r_cls + r x h를 통해 얻는다.
- 여기서 r은 weight parameter이고, h는 r_cls와 같은 크기의 Hanning window이다.
- target position은 r'_cls의 가장 큰 값에 의해 결정되고, sclae은 r_reg의 해당 회귀 결과에 기초하여 추정된다.
- motion token의 경우, 예측된 confidence score와 bounding box가 즉시 수집된다.
- Confidence threshold theta_conf가 적용되며, Head의 classification branch에서 주어진 confidence score가 임계값보다 낮으면 수집된 bounding box를 -무한으로 설정하여, 현재 프레임의 target object가 손실된 것으로 표시된다.
- theta_conf는 LaSOT의 경우 0.4로 설정되고, 나머지는 0.3으로 설정된다.
Comparisons to State-of-the-arts
1) LaSOT
- 280개의 test용 비디오로 구성되어 있다.
- 표1은 SoTAs와의 결과와 비교를 보여준다.
- light 아키텍쳐를 갖눈 SwinTrack-T-224가 0.672 SUC, 0.708 PRE 점수
- SOTA 성능에 도달하는 것을 관찰할 수 있으며,
- STARK-ST101(0.671 SUC), TransT(0.649 SUC)를 포함한 다른 트랜스포머 기반 추적기
- KeppTrack(0.671 SUC), SiamR-CNN(0.648 SUC)와 같은 복잡한 설계를 사용하는 기타 추적기와 비교하여 경쟁력 있다.
- 더 큰 backbone과 input size로, 본 논문의 가장 강력한 변형인 SwinTrack-B-384
- STARK-ST101과 KeepTrack을 4.2 absolute percentage points를 능가하는 0.713 SUC 점수로 새로운 기록을 세웠다.
2) LaSOT_ext
- 최근의 LaSOT_ext[10]은 150 extra video를 추가하여 LaSOT를 확장한 것
- 이러한 새로운 시퀀스는 많은 유사한 방해 요소가 추적에 어려움을 야기하기 때문에 어렵다.
- 이 데이터 세트와 관련된 추적기의 결과는 3번의 평균이다.
- KeepTrack은 복잡한 연관 기술을 사용하여 distractors를 처리하고 표1에서와 같이 유망한 0.482 SUC score를 달성한다.
- 복잡한 KeepTrack과 비교하여, SwinTrack-T-224는 단순하고 깔끔하지만 0.476 SUC 점수를 가지고 비교할 만한 성능을 보여준다.
- 또한 복잡한 설계로 인해 KeepTrack은 20fps 미만으로 실행되는 반면, SwinTrack-T-224는 KeepTrack보다 5배 빠른 98fps로 실행된다.
- 더 큰 모델을 사용할 때는 SwinTrack-B-384가 0.491 SUC 점수로 가장 우수한 성능을 보여준다.
3) TrackingNet
- TrackingNet[33]의 test set에서 서로 다른 추적기를 평가한다.
- 표1에서 SwinTrack-T-224가 0.811 SUC 점수로 비교할만한 결과를 달성한다는 것을 관찰한다.
- 더 큰 모델과 input size를 사용하여, SwinTrack-B-384는 0.840 SUC 점수
- STARK-ST101(0.820 SUC)와 TransT(0.814 SUC)보다 우수한 성능을 얻는다.
4) GOT-10k
- 테스트를 위한 180개의 비디오를 제공하며, 추적기는 train split만을 사용하여 훈련되어야 한다.
- 표1에서 SwinTrack-B-384는 0.724의 최고의 mAO를 달성하고, SwinTrack-T-224는 0.713의 mAO를 얻는 것을 알 수 있다.
- 두 모델 모두 STARK-ST101(0.688 mAO), TransT(0.671 mAO), TrDiMP(0.671 mAO)를 포함하여 다른 트랜스포머 기반 모델보다 성능이 뛰어나다.
5) TNL2k
- 700개의 테스트용 비디오가 포함된 새로 출시된 tracking dataset
- 표1에서 보고된 바와 같이, 두 모델은 다른 모델을 능가한다.
- SwinTrack-B-384는 0.559 SUC 점수로 새로운 최첨단 기술을 세웠다.
6) Efficiency Comparison
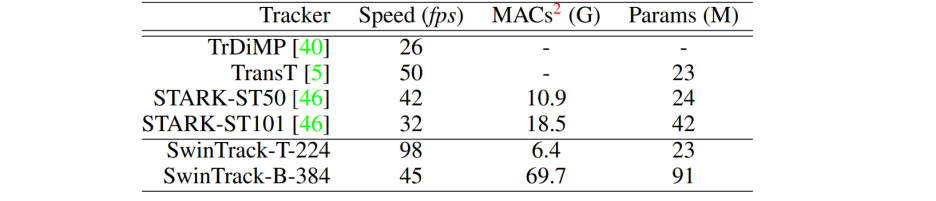
- 효율성과 복잡성 측면에서 SwinTrack과 다른 트랜스포머 기반 추적기의 비교를 보고한다.
- 표2에 나타난 바와 같이, small model이 장착된 SwinTrack-T-224는 98fps의 속도로 가장 빠르게 작동한다.
- 특히 STARK-ST101(32fps), STRAK-ST50(42fps)에 비해 2배, 3배 더 빠르다.
- 더 큰 모델을 사용했음에도 불구하고, SwinTrack-B-384는 여전히 위의 두 모델보다 빠르다.
Ablation Experiment

1) Comparison with ResNet Backbone
- Swin-Transformer backbone을 인기 있는 ResNet-50[18]과 비교한다.
- 표3에 나타난 바와 같이(① vs ②)
- Swin Transformer의 백본은 LaSOT에서 SUC 점수가 2.5%, LaSOT_ext에서 5.1% 만큼 성능을 크게 향상시킨다.
- 결과는 Swin Transformer가 제공하는 강력한 appearance modeling capability가 중요한 역할을 한다는 것을 보여준다.
2) Featrue Fusion
- 표3에 나타난 바와 같이(① vs ③)
- concatenated based fusion에 비해 cross attention-based fusion은 더 느린 속도로 실행
- 훨씬 더 많은 메모리를 차지하며 모든 데이터 세트에서 성능이 떨어진다.
- 속도가 느려지는 것은 추가 작업으로 인한 대기 시간 때문일 수 있다.
- parameter-sharing 전략은 parameters의 수를 줄일 뿐만 아니라 metric learning에도 도움이 된다.
3) Comparison with the query-based Decoder
- query는 일반적으로 비전 작업에서 트랜스포머 네트워크의 디코더에 흔히 채택된다.
- e.g., object query[3]과 target query[46]
- 그럼에도 불구하고, 표3에 나타난 바와 같이(① vs ④)
- 경험적 결과는 target query-based decoder가 2x training paris를 사용하더라도 모든 벤치마크에서 추적 성능을 저하시킨다는 것을 보여준다.
- 논의된 바와 같이, 한가지 가능한 이유는 classification에 적합하지 않기 때문이다.
- 게다가, 모든 종류의 object에 대한 일반적인 target query를 학습하는 것도 어려울 수 있다.
- 경험적 결과는 target query-based decoder가 2x training paris를 사용하더라도 모든 벤치마크에서 추적 성능을 저하시킨다는 것을 보여준다.
4) Position Encoding
- SwinTrack에 사용된 united positional encoding과 Transformer[38]의 original absolute position encoding을 비교한다.
- 참고로, 본 논문은 original absolute position encoding을 약간 수정한다.
- 2D embedding을 제외하고, token source의 index(e.g. template patch로부터 1 for the tokens, search region patch로부터 2 for the tokens) 또한 embedding된다.
- 참고로, 본 논문은 original absolute position encoding을 약간 수정한다.
- 표3에 나타난 바와 같이(① vs ⑤)
- united positional encoding을 사용하는 본 논문의 방법은 벤치마크에서 0.8-1.9 absolute percentage points로 개선된다.
- speed에서 neligible loss (98 vs 103) -> 별 차이 없음
5) Loss Function
- 표3에 나타난 바와 같이(① vs ⑥)
- 다양한 loss로 훈련된 모델이 효율성의 손실 없이 binary cross entropy(BCE) loss를 가진 모델을 크게 능가한다는 것을 관찰한다.
- 이 결과는 varifocal loss의 head의 classification branch가 IoU-aware response map을 생성하는 데 도움이 될 수 있으며
- 따라서 추적기가 추적 성능을 향상시키는 데 도움이 될 수 있음을 나타낸다.
- 다양한 loss로 훈련된 모델이 효율성의 손실 없이 binary cross entropy(BCE) loss를 가진 모델을 크게 능가한다는 것을 관찰한다.
6) Post Precessing
- highly discriminate Transformer architecture and IoU-aware classification loss가 hanning penalty window를 실행하는 것이 여전히 functional한지 궁금해 할 수 있으며, 이는 strong smooth movement 가정을 도입한다.
- 표3에 나타난 바와 같이(① vs ⑦) post-processing에서 Hanning penalty window를 제거하면
- LaSOT의 경우 1.0 SUC, GOT-10k의 경우 1.3 AO, 다른 데이터 세트의 SUC metric에서 1% 미만으로 성능이 떨어진다.
- 이는 강력한 smooth movement 가정이 여전히 추적기에 적용될 수 있음을 시사한다.
- 그러나 이전의 Transformer 기반 추적기[5]와 비교하여, penalty window post-processing가 있는 경우와 없는 경우의 성능 격차가 줄어들고 있다.
7) Effectiveness of motion token

- 비교 실험을 수행하여 motion token의 효과를 연구한다.
- 표4에 나타난 바와 같이(① vs ③ and ② vs ④)
- motion token이 있는 모델은 모든 데이터 세트, 특히 LaSOT_ext, GOT-10k에서 motion token이 없는 모델을 능가한다.
- 결과는 motion token이 추적기가 hard similar distractors를 처리하고,
- GOT-10k 테스트 세트의 시퀀스와 같은 short-term tracking을 안정화하는 데 도움이 될 수 있음을 나타낸다.
- 또한 motion token의 효과가 단순히 extra embedding vector에서 비롯되는지 여부를 연구한다.
- motion token을 학습 가능한 embedding token으로 대체하는 표4(⑤)와 같은 실험을 설정했다.
- 결과는 extra embedding vector가 object trajectory의 embedding의 효과를 나타내는 부정적인 영향을 미친다는 것을 보여준다.
Conclusion
- 본 연구에서는 트랜스포머 추적을 위한 간단하고도 강력한 baseline인 SwinTrack을 제시한다.
- SwinTrack에서 representation learning과 feature fusion은 모두 attention 매커니즘으로 구현된다.
- 광범위한 실험은 아키텍쳐의 효과를 입증한다.
- 또한 아키텍쳐 디자인에서 트랜스포머 모델의 유연성을 보여주는 historical object trajectory를 제공하여 추적기의 robustness를 향상시키기 위한 motion token을 제안한다.
- sequence-to-sequence 모델 아키텍쳐의 능력으로, context-rich tracker가 가능하며, 더 많은 contextual cues를 통합할 수 있다.
'Research' 카테고리의 다른 글
| [논문리뷰] OSTrack (0) | 2023.01.12 |
|---|---|
| [논문리뷰] HiFT (0) | 2023.01.07 |
| [논문리뷰] AiATrack (1) | 2022.12.29 |
| [논문리뷰] TREG (0) | 2022.12.20 |
| [논문리뷰] SparseTT (0) | 2022.12.19 |
