Joint Feature Learning and Relation Modeling for Tracking: A One-Stream Framework
Botao Ye 1 , 2 , Hong Chang 1 , 2 , Bingpeng Ma 2 , Shiguang Shan 1 , 2 , and Xilin Chen 1 , 2
Joint Feature Learning and Relation Modeling for Tracking: A One-Stream Framework
The current popular two-stream, two-stage tracking framework extracts the template and the search region features separately and then performs relation modeling, thus the extracted features lack the awareness of the target and have limited target-backgroun
arxiv.org
1. Abstract
- 현재 인기 있는 two-stream인 two-stage tracking framework
- template과 search region feature을 별도로 추출한 다음, relation modeling을 수행
➡ 추출된 features는 target에 대한 인식이 부족하고 target-background discriminability가 제한된다 ❗
- template과 search region feature을 별도로 추출한 다음, relation modeling을 수행
- 위의 문제를 해결하기 위해 novel one-stream tracking(OSTrack)을 제안
- template-search image paris를 bidirectional information flows과 연결하여 feature learning and relation modeling을 통합하는 방식
➡ 이러한 방식으로, discriminative target-oriented features는 mutual guidance에 의해 dynamically 추출될 수 있다. - extra heavy relation modeling module이 필요하지 않고, 구현이 고도로 병렬화되어 있으므로 제안된 추적기는 빠른 속도로 실행된다.
- template-search image paris를 bidirectional information flows과 연결하여 feature learning and relation modeling을 통합하는 방식
- Inference efficiency를 향상시키기 위해,
- one-stream framework에서 사전에 계산된 강력한 유사성을 기반으로, 네트워크 내에 candidate early elimination module을 제안한다.
- 통합 프레임워크로서 OSTrack은 여러 벤치마크에서 최첨단 성능을 달성하며, 특히 one-shot tracking benchmark GOT-10k에서 73.7%의 AO를 달성하여 기존 최고 결과 SwinTrack을 4.3% 향상시키는 인상적인 결과를 보여준다.
- 게다가 본 논문의 방법은 좋은 성능-속도 tradeoff를 유지하고 더 빠른 수렴을 보여준다.
2. Introduction

1) VOT(Visual Object Tracking) and two-stream & two-stage pipeline
- initial appearance만 주어졌을 때, 각 비디오 프레임에서 target을 localize하는 것을 목표로한다.
- target의 continuously changing and arbitrary nature은 지정된 target을 background와 효과적으로 구별할 수 있는 target appearance model을 학습하는 데 어려움을 제기한다.
- 현재 mainstream tracker는 일반적으로 공통의 two-stream and two-stage pipeline으로 이 문제를 해결
- 이는 teamplate and search region의 features가 별도로 추출(two-stream)
➡ 전체 과정이 feature extracion and relation modeling(two-stage) - two sequential steps로 분할된다는 것을 의미
- 이러한 natural pipeline은 "divide-and-conquer" 전략을 채택하고, 추적 성능 측면에서 놀라운 성공을 달성한다.
- 이는 teamplate and search region의 features가 별도로 추출(two-stream)
2) Weakness of two-stage & two-stream framework
- "Vanilla two-stream two-stage framework에 의해 추출된 features는 target을 인식하지 못한다."
- 즉, template and reach region 사이에 상호작용이 없기 때문에 각 이미지에 대해 추출된 features은 offline training 후에 결정된다.
➡ target의 continuously changing and arbitrary nature에 반하는 것이므로, limited target-background discriminative power로 이어진다. - target object의 category가 training dataset에 포함되지 않는 경우, 위의 문제는 특히 심각하다. (즉, one-shot tracking)
- 즉, template and reach region 사이에 상호작용이 없기 때문에 각 이미지에 대해 추출된 features은 offline training 후에 결정된다.
- "two-stage, two-stream framework는 performance-speed dilemma에 취약하다."
➡ feature fusion module의 계산 부담에 따라, 두가지 다른 전략이 일반적으로 사용된다.
- 그림 2(a)에 표시된 첫번째 유형 : 효율성⬆, 효과성⬇
cross-correlation [1, 27] 또는 discriminative correlation filter [2, 7]과 같은 single operator를 채택하기만 하면, simple linear operation이 discriminative information loss [5]로 이어지기 때문 - 그림 2(b)에 표시된 두번째 유형은 : 효율성⬇, 효과성⬆
complicated non-linear interaction에 의한 information loss를 해결하지만 (Transformer [44]), 파라미터의 수가 많고 반복적인 refinement를 사용하기 때문에 효율성이 떨어진다.
(e.g., 각 search image에 대해 STARK-S50 [50]은 RTX2080Ti GPU에서 feature extraction에 7.5ms, relation modeling에 14.1ms가 걸린다.)
- 그림 2(a)에 표시된 첫번째 유형 : 효율성⬆, 효과성⬇
3) 💡one-stream & one-stage framework💡
- Unified one-stream one-stage tracking framework를 통해 앞서 언급한 문제를 해결하기 시작했다.
- one-stream framework의 핵심
: 초기 단계에서(i.e., the raw image pair) template and search region 사이의 자유로운 정보 흐름을 연결
➡ target-oriented features를 추출
➡ discriminative information의 손실을 방지 - 구체적으로,
➡ flattened template and search region을 연결
➡ staked self-attention layers [44]에 공급하며 (구현에서 널리 사용되는 ViT [12]가 선택됨)
➡ 생성된 search region features는 더이상 matching 없이 target classification and regression에 직접 사용 가능- staked self-attention task
: template and reach region 간의 반복적인 feature matching을 가능하게 하여
➡ target-oriented feature extraction을 위한 mutual guidance를 가능하게 한다.
➡ 따라서 template and reach region feautres 모두 strong discriminative power로 추출될 수 있다.
- staked self-attention task
- 추가적으로,
➡ 제안된 프레임워크는 template and reach region을 연결하면,
➡ 하나의 stream framework가 고도로 병렬화되고,
➡ 추가적인 heavy relational modeling networks가 필요하지 않는다.
➡ 성능과 속도 사이에서 좋은 균형을 달성한다.
4) In-network early candidate elimination module
- 제안된 one-stream framework는 그림4와 같이
target and each part of the search region (i.e., candidates)의 유사성에 대한 강력한 선행을 제공하며,
이는 모델이 초기 단계에서도 background regions을 식별할 수 있음을 의미한다.- 이 현상은 one-stream framework의 효과를 검증하고, background에 속하는 후보들을 적시에 점진적으로 identifying and discarding하기 위한 in-network early candidate elimination module을 제안하도록 동기를 부여한다.
- 제안된 candidate elimination module
inference speed를 크게 향상시킬 뿐만 아니라, uninformative background regions이 feature matching에 미치는 부정적인 영향을 피한다.
5) Resulting
- 간단한 구조에도 불구하고, 제안된 추적기는 인상적인 성능을 달성하고, 여러 벤치마크에서 새로운 최첨단(SOTA)를 달성한다.
- 게다가 이것은 좋은 추론 효율성을 유지하고 SOTA Transformer 기반 추적기에 비해 더 빠른 수렴을 보여준다.
- 그림1에서 보는 바와 같이, 본 논문의 방법은 accuracy and inference speed 사이에서 좋은 균형을 이룬다.
6) Contribution
- feature extraction and relation modeling을 결합하여, 간단하고 깔끔하며 효과적인 one-stream one-stage tracking framework를 제안한다.
- target and each part of the search region 사이에서 early acquired similarity score의 prior에 의해 동기 부여되어, inference time을 줄이기 위해 in-network early candidate elimination module이 제안된다.
- performance, inference speed, convergence speed 측면에서 one-stream framework가 이전 SOTA two-stream trackers를 능가하는지 검증하기 위해 포괄적인 실험을 수행한다.
resulting tracker OSTrack은 여러 추적 벤치마크에 대한 새로운 최첨단 성능을 달성한다.
3. Related Work
Multiple tracking pipelind and early candidate elimination module과 관련된 adaptive inference method를 간략하게 검토
1) Tracking Pipelines
Feature extraction and relation modeling network의 서로 다른 계산 부담을 기반으로, 본 논문의 방법을 그림2의 두개의 서로 다른 two-stream and two-stage 방법과 비교한다.
- 초기 ; Siamese trackers [1, 27, 55]와 discriminative trackers [2, 7]는 그림 2(a)에 속한다.
1️⃣ 먼저 동일한 구조와 파라미터를 공유한 CNN backbone [18, 24]에 의해 template and search region의 features를 별도로 추출
2️⃣ 그런 다음 lightweight relation modeling network
(e.g., the cross-correlation layer [1, 26] in Siamese trackers and correlation filter [4, 19] in discriminative trackers)는 subsequent state estimation task를 위해 이러한 features를 융합할 책임이 있다.- 그러나 이러한 방법에서는 search region features에 따라 template feature를 조정할 수 없다.
- shallow and unidirectional relation modeling 전략은 information interaction에 불충분할 수 있다.
- 최근에는 더 나은 relation modeling을 위해 stacked transformer layers [44]가 도입되었다.
🔎 TransT [5] : iterative feature fusion을 위해 일련의 self-attention and cross-attention layers를 쌓는 것을 제안한다.
🔎 STARK [50] : CNN에 의해 pre-extracted template and search region features를 concatenate하여, multiple self-attention layers에 feed.
- 이러한 방법들은 그림2(b)에 속하는데, relation modeling module이 상대적으로 무겁고, bi-directional information interaction을 가능하게 한다.
- bi-directional heavy 구조는 성능 향상을 가져오지만 필연적으로 추론 속도를 낮춘다.
- 이와는 달리, 본 논문의 one-stream & one-stage 설계는 그림2(c)에 속한다.
- feature extraction and relation modeling을 unified pipeline으로 원활하게 결합한다.
- 제안된 방법은 적은 계산 비용으로 template and search region 사이의 자유로운 정보 흐름을 제공한다.
- mutual guidance에 의해 target-oriented features를 생성할 뿐만 아니라 training and testing time 측면에서 모두 효율적이다.
2) Adaptive Inference
- early candidate elimination module
: target and search region 사이의 유사성을 기반으로 potential background regions을 adaptively discarding하는 progressive process - 한 가지 관련 주제는 ViT 계산을 가속화하기 위해 제안된 vision transformers에서 adaptive inference [29, 39, 52]이다.
- DynamicViT [39]
: 추론 중 token을 폐기하기 위해 Gumbel-softmax trick으로 extra control gates를 훈련시킨다. - EViT [29]
: non-informative tokens을 직접 폐기하는 대신, potential information loss를 방지하기 위해 이것들을 융합한다.
- DynamicViT [39]
- 이러한 작업은 classification task와 밀접하게 결합되어 있으므로 추적에는 적합하지 않다.
➡ 대신 본 논문에서는 각 토큰을 target candidate로 처리한 다음, self-attention 연산에 의해 계산된 free similarity score를 통해 target과 가장 유사하지 않은 후보를 폐기한다.
4. Method
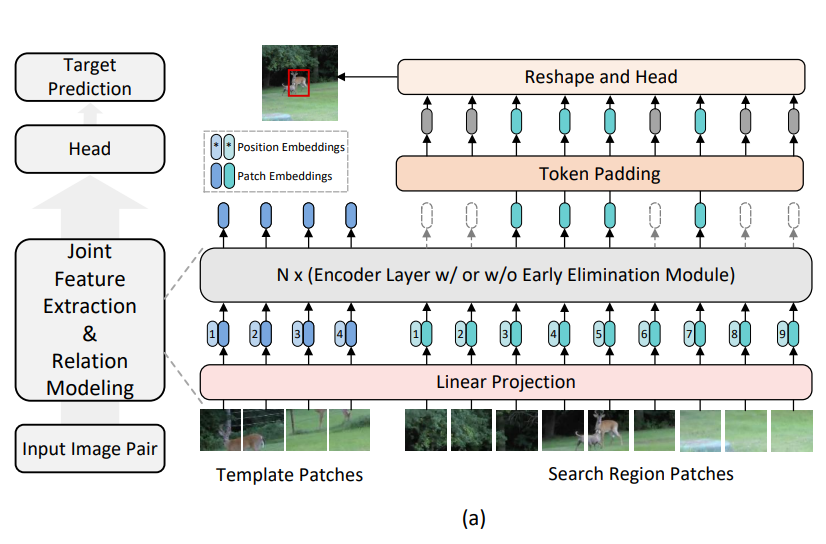
proposed one-stream tracker (OSTrack)에 대해 설명한다.
✔ Input image pairs : simultaneous feature extraction and relation modeling을 위해 ViT backbone에 feed
✔ Resulting search region features : subsequent target classification and regression에 직접 채택된다.
✔ 모델의 개요는 그림 3(a)에 나와 있다.
4.1. Joint Feature Extraction and Relation Modeling
1) Baseline
- Feature extraction and relation modeling module을 결합
➡ template의 contents와 search region 사이에 자유로운 정보 흐름을 구성할 것을 제안한다. - Main body : vanilla ViT [12]
➡Self-attention [44] operation의 global contextual modeling capacity는 본 논문의 목표에 완벽하게 부합하므로 - 기존 Vision Transformer의 아키텍쳐를 채택하면 공개적으로 사용가능한 pre-trained models [17, 42]도 다수 제공되므로, 시간이 많이 소요되는 pre-training 단계에서 벗어날 수 있다.
2) 과정
Input : 한 쌍의 이미지 (즉 template image patch and search region patch)
- 먼저 패치 z_p and x_p의 순서로 spliat and flattened
- 그 후, parameter E를 갖는 trainable linear projection layer
: Eq.1 and Eq.2에서와 같이, z_p and x_p를 D dimension latent space에 project(투영)하는 데 사용된다.
(이러한 projection의 output을 일반적으로 patch embedding [12]이라고 한다.) - Learnable 1D position embedding P_z and P_x
: template and search region의 patch embedding에 별도로 추가
➡ final template token embedding and search region token embedding이 생성된다.- addition identity embeddings(BERT[11]에서와 같이 template or search region에 속하는 토큰을 나타내기 위해)을 추가하거나, relative positional embeddings을 채택하는 것이 성능에 유익한지 확인하기 위해 ablation studies를 수행하고 현저한 개선이 없음을 관찰하므로 단순성을 위해 생략한다.
- Token sequence H^0_z and H^0_x는 H^0_zx로 concatened
➡ resulting vector H^0_zx는 several Transformer encoder layers [12]으로 fed.
추가 설명
✨ vanilla ViT [12]와 달리, 본 논문에서는 inference 효율성을 위해 그림 3(b)에 표시된 것처럼 제안된 early candidate eliminating module을 일부 encoder layers에 삽입하고, 세부 사항은 3.2에 제시한다.
✨ 특히 concatened features의 self-attention을 채택하면, 전체 프레임워크가 cross-attention [5]과 비교하여 고도로 병렬화된다.
✨ template images도 각 search frame에 대해 ViT로 공급되지만, 병렬 구조가 높고 search region token 수에 비해 적기 때문에 추론 속도에 미치는 영향은 미미하다.
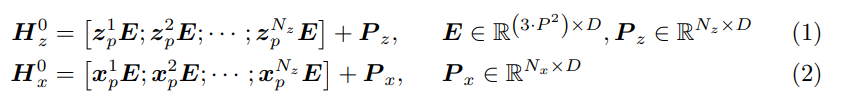
3) Analysis
Self-attention mechanism [44]의 관점에서, 제안된 프레임워크가 feature extraction and relation modeling을 동시에 실현할 수 있는 본질적인 이유를 추가로 분석한다.
- 본 논문의 접근 방식에서 Self-attention operation A의 결과는 (3)으로 나타낼 수 있다.
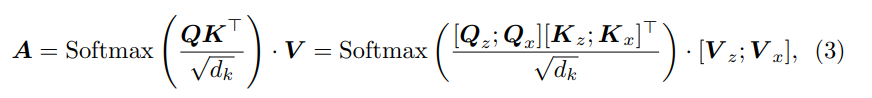
- Eq.3의 attention weights 계산은 (4)로 확장될 수 있다.
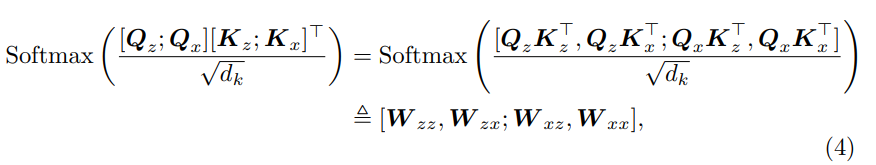
- A의 결과는 (5)로 나타낼 수 있다.
- Eq.5의 오른쪽 부분에서,
W_xzV_z : 서로 다른 이미지 부분의 유사성에 기초하여, iter-image feature (relation extraction)을 aggregating
W_xxV_x : intra-image feature (feature extraction)을 aggregating하는 역할을 한다. - 따라서 feature extraction and relation modeling은 self-attention operation으로 수행될 수 있다.
- Eq.5의 오른쪽 부분에서,
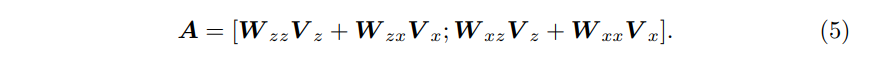
4) Comparisons with Two-Stream Transformer Fusion Trackers
- Previous two-stream Transformer fusion trackers [5, 30]
: 모두 template and search region의 features이 먼저 별도로 추출되는 Siamese framework를 채택하고, extracted features을 융합하는데만 transformer layer가 채택된다.- 따라서 이러한 방법의 extracted features은 적응적이지 않으며, 일부 discriminative 정보를 잃을 수 있으며 이는 복구할 수 없다.
- 반면, OSTrack은 첫번째 단계에서 linearly projected template and search region images를 직접 concatenate하므로, feature extraction and relation modeling이 원활하게 통합되고 template and search region의 mutual guidance를 통해 target-oriented features가 추출될 수 있다.
- Previous Transformer
: fusion trackers는 ImageNet [10] pre-trained backbone networks [18, 32]만 사용하고, transformer layers를 무작위로 초기화하여 수렴 속도를 저하시킨다.- 반면, OSTrack은 pre-trained ViT models의 이점을 더 빠른 수렴을 위해 사용한다.
- one-stream framework는 3.2에서 제시된 것처럼 모델 성능과 추론 속도를 더욱 향상시키기 위해 쓸모없는 background region을 식별하고 폐기할 수 있는 가능성을 제공한다.
4.2. Early Candidate Elimination
1) 이전 추적기들과의 비교 및 one-stream framework 시각화

- search region의 각 토큰은 target candidate로 간주되고,
각 template token은 target object의 일부로 간주될 수 있다. - 이전 추적기들은
: feature extraction and relation modeling 동안 모든 candidates를 유지하는 반면, background regions은 네트워크의 최종 출력 (i.e., classification score map)까지 식별되지 않는다. - 그러나 one-stream framework
: target and each candidate 간의 유사성에 대한 강력한 선행을 제공한다.- 그림 4와 같이, search region의 attention weights는 ViT의 초기 단계 (e.g., layer 4)에서 foreground objects를 강조한 다음, 점진적으로 target에 초점을 맞춘다.
- 이 특성은 네트워크 내부의 background regions에 속하는 candidates를 점진적으로 식별하고 제거하는 것을 가능하게 한다.
- 따라서 ViT 초기 단계에서 배경에 속하는 후보들을 점진적으로 제거하여 계산 부담을 줄이고, feature learning에서 noisy background regions의 부정적인 영향을 피하는 early candidate elimination module을 제안한다.
2) Candidate Elimination
ViT에서 self-attention operation은 각 token pair 간의 dot product similarity로 측정되는 normalized importances [44]를 가진 토큰의 spatial aggregation으로 볼 수 있다는 것을 기억
- 구체적으로 각 template token은 (6)으로 계산된다.
- attention weight w^i_x
: template part h^i_z와 모든 search region tokens (candidates) 사이의 유사성을 결정한다. - w^i_x의 j-th item
: h^i_z와 j-th candidate 사이의 유사성을 결정한다.
- attention weight w^i_x
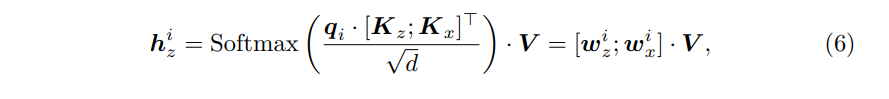
- 그러나 input templates는 일반적으로 target and each candidate 간의 유사성을 계산할 때 노이즈를 발생시키는 background region을 포함한다.
- 따라서 모든 template parts w^i_x에 대한 각 후보의 유사성을 종합하는 대신,
대표적인 유사성으로 w^pi_x (original template image의 center part에 해당하는 pi-th token)을 취한다. - 이는 center template 부분이 target을 나타내 위해 self-attention을 통해 충분한 정보를 수집했기 때문에 상당히 합리적이다.
- 따라서 모든 template parts w^i_x에 대한 각 후보의 유사성을 종합하는 대신,
- 추가적으로, different template token choices의 효과를 비교한다.
- Multi-head self-attention이 ViT에 사용된다는 점을 고려하면, Multiple similarity scores w^pi_x가 있다, m=1, ..., M(attention heads [44]의 총 개수)
- target과 each candidate의 final similarity score 역할을 하는 barw^pi_x = sum w^pi_x (m) / M으로 모든 헤드의 유사성 점수를 평균화한다.
- One candidate는 target과의 유사성 점수가 낮을 경우 background region이 될 가능성이 높다.
- 따라서 barw^pi_x(k는 하이퍼파라미터, token keeping ratio는 k/n으로 정의)에서 k largest (top-k) 에 해당하는 candidates만 유지하고 나머지는 제거한다.
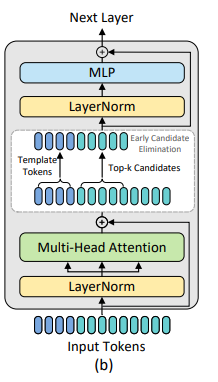
- 제안된 candidate elimination module은 그림 3(b)에 제시된 encoder layer에서 multi-head attention operation [44] 후 삽입된다.
- 또한 all remaining candidates의 원래 순서를 기록하여, 최종 단계에서 복구할 수 있도록 한다.
3) Candidate Restoration
- 앞서 언급한 candidate elimination module은 candidates의 원래 순서를 방해하여 3.3에서 설명한 대로 candidate sequence를 다시 feature map으로 재구성하는 것이 불가능하므로, 나머지 candidates의 원래 순서를 복원한 후 누락된 위치를 pad.
- 폐기된 후보들은 관련이 없는 배경 영역에 속하기 때문에 classification and regression tasks에 영향을 미치지 않는다.
- 다시 말해, 그들은 reshaping operation을 위한 placeholders(자리 표시자) 역할을 할 뿐이다.
- 따라서 💛먼저 남은 후보들의 순서를 복원한 다음, 그들 사이에 제로 패드💛를 넣는다.
4) Visualization

- early candidate elimination module의 동작을 추가로 조사하기 위해, 그림5에서 진행 과정을 시각화한다.
- search region에서 관련 없는 토큰을 반복적으로 폐기함으로써
➡ OSTrack은 계산 부담을 크게 줄일 뿐만 아니라
➡ feature learning에서 noisy background regions의 부정적인 영향을 피한다.
- search region에서 관련 없는 토큰을 반복적으로 폐기함으로써
4.3. Head and Loss
1) Head
- 1️⃣ 먼저 search region tokens의 padded sequence를 2D spatial feature map으로 re-interpret한 다음
2️⃣ 각 출력에 대해 L stacked Conv-BN-ReLU layers로 구성된 fully convolutional network (FCN)에 공급된다. - 3️⃣ FCN의 출력 구성
- target classification score map P
- resolution 감소로 인한 discretization error를 보정하기 위한 local offset O
- normalized bounding box size (i.e. whidth and height) S
- classification이 가장 높은 position은 target position (i.e. (x_d, y_d) = argmax_(x, y) P_xy)로 간주되며 finial target bounding box는 (7)과 같이 구해진다.
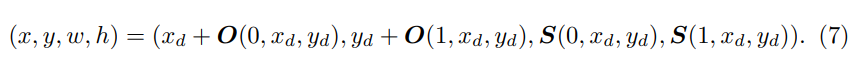
2) Loss
- Training 동안 classification and regression loss가 모두 사용된다.
- classificaion loss
: weighted focal loss [25]를 채택한다. - Boungding box regression loss
: predicted bounding box를 사용하면 l1 loss and generalized IoU loss [40] - 마지막으로 overall loss function은 (8)이다.
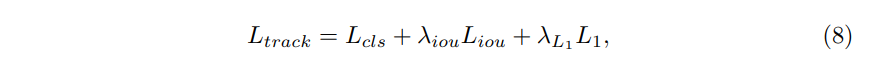
5. Experiments
구현 세부 정보를 소개한 후, 먼저 7개의 다른 벤치마크에서 각각의 SOTA 모델과 OSTrack을 비교한다.
그런 다음, 각 구성요소 및 다양한 설계 선택사항의 영향을 분석하기 위한 ablation study가 제공된다.
5.1. Implementation Details
본 논문의 추적기는 파이토치를 사용하여 파이썬에서 구현된다.
모델은 4개의 NVIDIA A100 GPUs에서 훈련된다.
Inference speed는 single NVIDIA RTX2080Ti GPU에서 테스트된다.
1) Model
- MAE [17]로 pre-trained된 vanilla ViT-Base [12] 모델은 joint feature extraction and relation modeling을 위한 백본으로 채택된다.
- Head
: lightweight FCN으로 3개의 outputs 각각에 대해 4개의 Conv-BN-ReLU layers가 stacked - 각 candidate elimination module
✔ keeping ratio (로우) : 0.7
✔ [39]를 따라 ViT의 layers 4, 7, 10에 총3개의 candidate elimination module이 삽입된다. - OSTrack의 확장성을 보여주기 위해 서로 다른 input image pair resolution을 가진 두가지 변형을 제시한다.
- OSTrack-256
: Template (128x128 pixels), Search region (256x256 pixels) - OSTrack-384
: Template (192x192 pixels), Search region (384x384 pixels)
- OSTrack-256
2) Training
- Training Dataset
: COCO [31], LaSOT [14], GOT-10k [20] (1k forbidden sequences from GOT-10k training set은 convention [50]에 따라 제거되었다.), TrackingNet [37]이 training을 위해 사용된다. - Data augmentation
: horizontal flip and brightness jittering - 각 GPU는 32개의 image paris를 보유
- Total batch size : 128
- Optimizer : AdamW
- weight decay : 10^-4
- backbone에 대한 initial learning rate : 4x10^-5
- 다른 파라미터들 : 4x10^-4
- Total training epoch : epoch 당 60k image pairs를 사용하여 300으로 설정되며, 240 epochs 이후 학습률을 10배 감소시킨다.
3) Inference
- Inference 동안, Hanning window penalty는 일반적인 practice [5, 55]에 따라 tracking에 앞서 positional을 활용하기 위해 채택된다.
- 구체적으로, 본 논문에서는 단순히 classification map P에 같은 크기의 Hanning window를 곱하면
➡ multiplication(곱셈) 후 점수가 가장 높은 상자가 추적 결과로 선택될 것이다.
- 구체적으로, 본 논문에서는 단순히 classification map P에 같은 크기의 Hanning window를 곱하면
5.2. Comparison with State-of-the-arts
제안된 모델의 효과를 입증하기 위해 7개의 다른 벤치마크에서 SOTA 추적기들과 비교한다.
1) GOT-10k
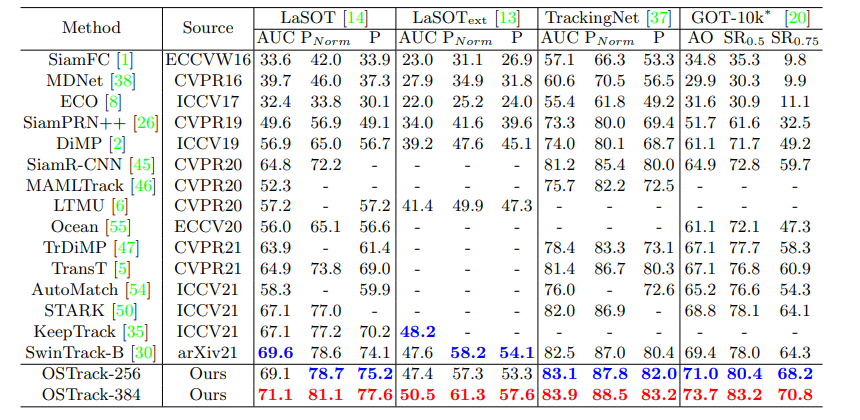
🔎 GOT-10k [20] Test set
- one-shot tracking rule을 사용한다.
- 즉, 추적기는 GOT-10k training split에 대해서만 훈련되어야 하며
- train and test splits 사이의 object classes는 중복되지 않는다.
- 이러한 protocol을 따라 모델을 훈련하고 공식 평가 서버에 제출하여 결과를 평가한다.
🔎 Result
- 표1에서 보고된 바와 같이, AO에서 OSTrack-384 및 OSTrack-256은 SwinTrack-B [30]보다 각각 1.6% 4.3% 우수하다.
- OSTrack-384의 SR_0.75 점수는 70.8%에 도달하며, SwinTrack-B를 6.5% 능가한다.
- 이는 accurate target-background discrimination and bounding box regression 모두에서 추적기의 능력을 검증한다.
- 또한, 이러한 one-shot 벤치마크의 높은 성능은 본 논문의 one-stream tracking framework가 mutual guidance를 통해 보이지 않는 클래스에 대해 더 많은 discriminative features를 추출할 수 있음을 보여준다.
2) Lasot
🔎 Lasot [14]
- Test를 위한 280개의 비디오를 포함하는 까다로운 large-scale long-term tracking benchmark
🔎 Result
- 표1에서 OSTrack의 결과를 이전 SOTA tracker와 비교한다.
- smaller input resollution을 가진 제안된 추적기 (즉, OSTrack-256)은 이미 SwinTrack-B와 비슷한 성능을 얻고 있음을 보여준다.
- 또한 OSTrack-256은 105.4fps의 빠른 inference speed로 실행되며, SwinTrack-B (52fps) 보다 2배 빠르다.
- 이는 OSTrack이 정확도와 추론 속도 사이에서 탁월한 균형을 달성한다는 것을 나타낸다.
- input resolution을 높임으로써, OSTrack-384는 LaSOT의 AUC를 71.1%로 더욱 향상시키고 새로운 state-of-the-art를 달성한다.
3) TrackingNet
🔎 TrackingNet [37]
- 다양한 target classes를 다루는 테스트를 위한 511개의 시퀀스가 포함되어 있다.
🔎 Result
- 표1은 AUC에서 각각 OSTrack-256과 OSTrack-384가 SwinTrack-B를 0.6%, 1.4% 능가한다는 것을 보여준다.
- 게다가 두 모델 모두 SwinTrack-B보다 빠르다.
4) LaSOT_ext
🔎 LaSOT_ext
- 최근 출시된 LaSOT의 확장판
- 15개의 object classes로부터 150개의 추가 비디오로 구성되어 있다.
🔎 Result
- 표1에서 이전 SOTA tracker KeepTrack [35]는 복잡한 association network를 설계하고, 18.3fps로 실행된다.
- 대조적으로 본 논문에서의 단순한 one-stream tracker OSTrack-256은 성능은 약간 낮지만 105.4fps로 실행된다.
- OSTrack-384는 50.5%의 새로운 state-of-the-art AUC 점수를 달성하는 동시에 58.1FPS에서 실행되어 KeepTrack보다 AUC 점수가 2.3% 높고 3배 빠르다.
5) NFS, UAV123, TNL2K

🔎 NFS, UAV123, TNL2K
- 각각 100, 123, 700개의 video sequences를 포함한다.
🔎 Result
- 표2의 결과는 OSTrack-384가 세가지 벤치마크에서 모두 최고의 성능을 달성하여 OSTrack의 강력한 일반화 가능성을 보여준다.
5.3. Ablation Study and Analysis
1) The Effect of Early Candidate Elimination Module

- 표1은 input image pairs의 input resolution을 높이면 상당한 성능 향상을 가져올 수 있음을 보여준다.
- 그러나 input resolution과 관련된 quadratic complexity는 단순히 input resolution을 증가시키는 것을 inference time에 감당할 수 없게 만든다.
- 제안된 early candidate elimination module은 위의 문제를 잘 해결한다.
- Inference speed(FPS)
multiply-accumulate computations (MACs)
tracking performance
위의 세가지 측면에서 early candidate elimination module이 표3의 여러 벤치마크에 미치는 영향을 제시한다. - different input search region resolutions에 대한 효과도 제시된다.
- Inference speed(FPS)
- 표3은 early candidate elimination module이 대부분의 경우 성능을 약간 향상시키면서 계산을 크게 줄이고 추론 속도를 높일 수 있음을 보여준다.
- 이는 제안된 모듈이 노이즈가 많은 배경 영역이 feature learning에 미치는 부정적인 영향을 완화한다는 것을 보여준다.
- 예를 들어, OSTrack-256에 early candidate elimination module을 추가하면, MACs가 25.9% 감소하고, tracking speed가 13.2% 증가하며, LaSOT AUC가 0.4% 증가한다.
- 게다가 larger input resolution은 이 모듈로부터 더 많은 이점을 얻는다.
- 예를 들어 OSTrack-384의 속도가 40.3% 증가했다.
2) Different Pre-training Methods
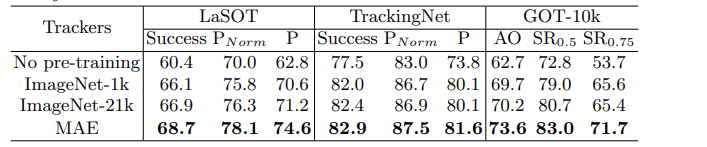
- Previous Transformer fusion trackers [5, 30, 50]가 transformer layers의 가중치를 무작위로 초기화하는 동안
VS 본 논문의 joint feature learning and relation modeling은 pre-trained weights의 혜택을 직접 받을 수 있다. - 4개의 다른 pre-training 전략을 비교함으로써 추적 성능에 대한 different pre-training methods의 효과를 조사한다.
1️⃣ no-pretraining
2️⃣ ImageNet-1k [10] pre-trained model provided by [43]
3️⃣ ImageNet-21k [41] pre-trained model provided by [42]
4️⃣ unsupervised pre-training model MAE [17]. - 표4의 결과에서 알 수 있듯이 model weight initialization을 위해 pre-training이 필요하다.
- 흥미롭게도, unsupervised pretraining method MAE가 ImageNet을 사용하여 supervised pre-training된 방법보다 더 나은 추적 성능을 제공한다는 것을 관찰한다.
- 이것이 추적 작업에 맞춘 더 나은 pre-training 전략을 설계하도록 영감을 줄 수 있기를 바란다.
5.4. Aligned Comparison with SOTA Two-stream Trackers

- 성능 향상이 제안된 one-stream 구조에 의해 초래되는지 아니면 순수하게 ViT의 우수성에 의해 초래되는지 궁금해 할 수 있다.
- 따라서 본 논문에서는 backbone and head 구조의 영향 요인을 제거하여 two SOTA two-stream transformer fusion trackers[30, 50]과 비교한다.
- 구체적으로 말하면 다음과 같이 공정한 비교를 위해 두개의 이전 SOTA two-stream trackers (STARSK-S [50] and SwinTrack [30])을 본 논문의 추적기와 정렬한다.
- 그들의 백본을 사전 훈련된 동일한 ViT로 교체하고 OSTrack-256과 동일한 input resolution, head structure, training objective를 설정한다.
- 나머지 실험 설정은 원래 논문과 동일하게 유지된다.
- 💡 특징 1
➡ 재구현된 two-stream 추적기는 초기에 발표된 성능과 비교하여 동등하거나 더 강력한 성능을 보여주지만,
➡ 여전히 본 논문의 one-stream 구조의 효과를 보여주는 OSTrack에 비해 뒤쳐져 있다. - 💡 특징 2
➡ OSTrack이 one-shot benchmark GOT-10k에서 이전의 two-stream tracker를 크게 능가한다는 것을 관찰
➡ 이는 어려운 시나리오에서 one-stream framework의 이점을 더욱 입증한다.- 실제로 test set의 object class가 training set와 완전히 다르기 때문에 two-stream framework에 의해 추출된 feature의 discriminative power는 제한적이다.
- 한편, template feature and search region 간의 반복적인 상호 작용을 통해 OSTrack은 mutual guidance를 통해 more discriminative features를 추출할 수 있다.
- 💡 특징 3
➡ Two-stream SOTA tracker와 달리, OSTrack은 joint feature extraction and relation modeling module의 높은 병렬성을 유지하면서 extra heavy relation modeling module은 무시한다.
➡ 따라서 동일한 backbone network를 채택할 경우 제안된 one-stream framework는 STRAK(40.2FPS faster) and SwinTrack (25.6 FPS faster) 보다 훨씬 빠르다. - 💡 특징 4
게다가 OSTrack은 수렴하기 위해 더 적은 training image pairs를 필요로 한다.
5.5. Discriminative Region Visualization

- 제안된 one-stream tracker의 효과를 더 잘 설명하기 위해, 그림6에서 OSTrack과 SOTA two-stream tracker (SwinTrack-alinged)에 의해 추출된 backbone features의 discriminative regions을 시각화한다.
- SwinTrack-aligned의 백본에 의해 추출된 features
➡ target awareness의 부족으로 인해 제한된 target-background discriminative power를 보여주고,
➡ 일부 중요한 target 정보 (e.g., 그림 6에서 head and helmet)를 잃을 수 있으며, 이는 복구할 수 없다. - 반대로, 제안된 initial fusion mechanism
➡ 첫번째 단계에서 template and search region 간의 relation modeling을 가능하게 하기 때문에
➡ OSTrack은 discriminative target oriented features를 추출할 수 있다.
6. Conclusion
- 본 연구는 Siamese과 같은 pipeline에서 벗어난
➡ Vision Transformer 기반의 단순하고 깔끔한 high-performance one-stream tracking framework를 제안한다. - 제안된 추적기는 feature extraction and relation modeling tasks를 결합
➡ 성능과 추론 속도 사이의 균형을 잘 보여준다. - 또한 추적 추론 속도를 크게 향상시키는 background region에 속하는 search region token을 점진적으로 폐기하는 early candidate elimination module을 추가로 제안한다.
- 광범위한 실험에 따르면 제안된 one-stream tracker는 특히 one-shot protocol에서, multiple benchmarks에서 이전 방법보다 훨씬 더 나은 성능을 발휘한다.
- 이 작업이 one-stream tracking framework에 더 많은 관심을 끌 수 있을 것으로 기대한다.
'Research' 카테고리의 다른 글
| [Object Tracking] DCF-based Tracker (0) | 2023.01.26 |
|---|---|
| [Object Tracking] Transformer-based Tracker (0) | 2023.01.26 |
| [논문리뷰] HiFT (0) | 2023.01.07 |
| [논문리뷰] AiATrack (1) | 2022.12.29 |
| [논문리뷰] SwinTrack (1) | 2022.12.20 |
