
💡 계속 업데이트 예정
이 외에도 Transformer를 이용한 트래커들이 많지만, VOT 챌린지에서 EAO 점수가 높은 트래커 위주로 제가 리뷰한 논문을 정리하였습니다. (간단한 모델 아키텍쳐와 특징이나 장점, 단점, 구성을 정리하려고 만든 글입니다. 더 사제한 내용을 보시려면 논문리뷰 포스팅 글을 참고해주세요.)
Transformer
- 최근에는 트랜스포머를 사용하는 여러 추적기가 도입되었다.
- 트랜스포머는 일반적으로 target object를 localize & bounding box를 regression 위해 discriminative features를 예측하는 데 사용된다.
- 인코더
: training features 처리 - 디코더
: cross-attention layers를 사용하여 training and test features를 융합,
discriminative features 를 계산
- 인코더
- 트랜스포머를 이용하여 추적하는 방식에는 여러가지가 있다.
- 트랜스포머와 백본 조합
- Pure Transformer : SparseTT(SwinTransformer 백본), SwinTrack(SwinTransformer 백본)
- CNN + Transformer : DTT, TransT, TrDiMP, STARK, TREG
- 아키텍쳐 구조(Pipeline)
- Siamese Pipeline : SparseTT, TrDiMP, SwinTrack
- DCF Pipeline :
- Siamese + DCF : DTT
- 그 외 customed : TREG
- 트랜스포머와 백본 조합
(DTT, TrDiMP, AiATrack) : 인코더 디코더 구조 비슷 (?)
Transformer trackers
DTT
(High-performance discriminative tracking with transformers. )
DTT
High-Performance Discriminative Tracking with Transformers 1. Abstract End-to-end discriminat...
blog.naver.com


⚠ 계산된 features를 target의 location and bounding box를 예측하는 두 개의 네트워크에 공급한다.
<참고 by SparseTT>
- TrDiMP의 단점을 알아차린 DTT는 cross-correlation을 Transformer로 대체하여 response score 대신, fused features을 생성할 것을 제안한다.
- fused features는 response score보다 풍부한 semantic information을 포함하기 때문에 이러한 방법은 이전 Siamese 추적기보다 훨씬 정확한 추적에 도달한다.
TransT
(Transformer tracking)
[논문리뷰] Transformer Tracking
Transformer Tracking Abstract 1. 상관관계 : 추적 분야에서 중요한 역할을 한다. 특히 최근 인기있는 ...
blog.naver.com

🎀 특징
- multiple self and cross attention modules로 구성된 feature fusion network를 사용한다.
- fused output features는 target classifier and bounding box regressor로 공급된다.
- iterative feature fusion을 위해 일련의 self-attention and cross-attention layers를 쌓는 것이 특징이다.
🎀 단점
- relation modeling module이 상대적으로 무겁고, bi-directional information interaction을 가능하게 하지만,
bi-directional heavy 구조는 성능 향상을 가져오지만 필연적으로 추론 속도를 낮춘다.
<참고 by SparseTT>
- TrDiMP의 단점을 알아차린 TransT는 cross-correlation을 Transformer로 대체하여 response score 대신, fused features을 생성할 것을 제안한다.
- fused features는 response score보다 풍부한 semantic information을 포함하기 때문에 이러한 방법은 이전 Siamese 추적기보다 훨씬 정확한 추적에 도달한다.
TrDiMP
(Transformer meets tracker: Exploiting temporal context for robust visual tracking.)
[논문리뷰] Transformer Meets Tracker
Transformer Meets Tracker: Exploiting Temporal Context for Robust Visual Tracking Abstract...
blog.naver.com

- DiMP [1] model predictor를 채택하여 트랜스포머 인코더의 output features이 training samples로 주어졌을 때, model weights를 생성한다.
- 그 후, target model은 트랜스포머 디코더에 의해 생성된 output features에 예측된 weights를 적용하여 target score map을 계산한다.
- TrDiMP는 bounding box regression을 위해 probabilistic IoUNet [16]을 채택한다.
- TrDiMP는 본 논문의 추적기와 유사하게, target state information을 인코딩하지만,
트랜스포머 앞에 있는 두 개의 인코딩 모듈을 사용하는 대신, 디코더에서 두 개의 서로 다른 cross attention 모듈을 통해 통합한다.
<참고 by SparseTT>
- TrDiMP는 CNN backbone을 사용하여, 두개의 branch를 구축한 후, 각각 Transformer encoder과 Transformer decoder를 사용하는 Siamese-like tracking pipeline을 설계한다.
- 여기서 Transformer는 target template과 search regions을 향상시키기 위해 사용된다.
- 이전 Siamses tracker와 유사하게, TrDiMP는 cross-correlation을 적용하여 target template과 search region 간의 유사성을 측정하며, 이는 추적기의 고성능 추적을 방해할 수 있다.
STARK
(Learning spatio-temporal transformer for visual tracking.)
논문 리뷰(Learning Spatio-Temporal Transformer for Visual Tracking)
Learning Spatio-Temporal Transformer for Visual Tracking 용어 정리 end-to-end : 머신러닝은 전...
blog.naver.com

⚠ 앞서 언급한 트랜스포머 기반 추적기와 달리, STARK [63]은 DETR[6]으로부터 트랜스포머 아키텍쳐를 채택
🎀 과정
- 트랜스포머 디코더에서 training and test features를 융합하는 대신, 전체 트랜스포머에 의해 함께 stacked and processed.
- 그런 다음 single object query를 통해 디코더 output이 생성되며, 이것은 트랜스포머 인코더 features과 fused된다.
- 그런 다음 이러한 features는 target의 bounding box를 직접 예측하기 위해 추가로 처리된다.
🎀 특징
- CNN에 의해 pre-extracted template and search region features를 concatenate하여,
multiple self-attention layers에 feed하는 것이 특징이다.
🎀 단점
- relation modeling module이 상대적으로 무겁고, bi-directional information interaction을 가능하게 하지만,
bi-directional heavy 구조는 성능 향상을 가져오지만 필연적으로 추론 속도를 낮춘다.
<참고 by SparseTT>
- DETR에서 영감을 받아, STARK는 target tracking을 bounding box prediction problem으로 casts하고, 이것을 인코더-디코더 트랜스포머로 해결한다.
- 인코더는 target과 search region 사이의 global spatio-temporal feature dependencies를 모델링하고,
- 디코더는 targets의 spatial positions을 예측하기 위해 query embedding을 학습한다.
- 이것은 시각적 추적에서 우수한 성능을 달성한다.
ToMP
(Transforming Model Prediction for Tracking)
[논문리뷰] ToMP
Transforming Model Prediction for Tracking Christoph Mayer, Martin Danelljan, Goutam Bhat, Matthieu Paul, Danda Pani Paudel, Fisher Yu, Luc Van Gool Transforming Model Prediction for Tracking Optimization based tracking methods have been widely successful
nozzi-study.tistory.com



- ToMP 추적기는 DETR [6]의 동일한 트랜스포머 아키텍쳐를 사용하지만 model optimizer를 대체한다.
- 결과적으로 트랜스포머 기반 model predictor는 두 개의 별도 모델들의 weights를 추정한다. : target classifier and the bounding box regressor.
OSTrack
(Transforming Model Prediction for Tracking)
[논문리뷰] OSTrack
Joint Feature Learning and Relation Modeling for Tracking: A One-Stream Framework Botao Ye 1 , 2 , Hong Chang 1 , 2 , Bingpeng Ma 2 , Shiguang Shan 1 , 2 , and Xilin Chen 1 , 2 Joint Feature Learning and Relation Modeling for Tracking: A One-Stream Framewo
nozzi-study.tistory.com



🎀 특징
- one-stream & one-stage 설계를 사용한다.
🎀 단점
DualTFR
(Learning Tracking Representations via Dual-Branch Fully Transformer Networks)
[논문리뷰] DualTFR
Learning Tracking Representations via Dual-Branch Fully Transformer Networks Abstract 본 논...
blog.naver.com
TrTr
(Visual Tracking with Transformer)
TrTr
TrTr: Visual Tracking with Transformer Abstract Template-based Discriminative trackers robus...
blog.naver.com
MixFormer
(End-to-End Tracking with Iterative Mixed Attention)
[논문리뷰] MixFormer
MixFormer: End-to-End Tracking with Iterative Mixed Attention Abstract Tracking의 pipeline...
blog.naver.com
AiATrack
(Attention in Attention for Transformer Visual Tracking)
[논문리뷰] AiATrack
AiATrack : Attention in Attention for Transformer Visual Tracking Shenyuan Gao1 , Chunluan Zhou2 , Chao Ma3 , Xinggang Wang1 , Junsong Yuan4 AiATrack: Attention in Attention for Transformer Visual Tracking Transformer trackers have achieved impressive adva
nozzi-study.tistory.com

SparseTT
(Visual Tracking with Sparse Transformers)
[논문리뷰] SparseTT
SparseTT: Visual Tracking with Sparse Transformers Zhihong Fu , Zehua Fu , Qingjie Liu∗ , Wenrui Cai and Yunhong Wang SparseTT: Visual Tracking with Sparse Transformers Transformers have been successfully applied to the visual tracking task and significa
nozzi-study.tistory.com



🎀 목적
- 트랜스포머의 self-attention은 long-range dependencies를 모델링하는 데 특화되어 있어, global information을 잘 포착하지만, search regions에서 가장 관련성이 높은 정보에 초점을 맞추지 못하는 어려움 해결
🎀 특징
- primary information에 중점을 두도록 설계되어 있어 severe target deformation, partial occlusion, scale variation 등에서도 bounding box가 더 정확 (target focus network)
- sparse Transformer로 실현되는 search region의 가장 관련성이 높은 정보에 집중
- target deformation, partial occlusion, scale variation 등을 처리하는 강력한 능력을 가진 sparse transformer 기반 Siamese tracking framework
- TransT, DTT에서 발전된 형태
TransT, DTT는 cross-correlation을 Transformer로 대체하여 추적 성능을 향상시킨다.
- 그러나 트랜스포머르 추적기를 구축하면 새로운 문제가 발생한다.
- 트랜스포머의 self-attention의 global perspective는 primary information(search regions의 target)는 under-focused지만, secondary information(search regions의 background)는 over-focused되어, foreground와 background 사이의 edge region이 blurred되어, 추적 성능이 저하된다.
- 위의 문제에 대한 해결책인 SpareTT 모델 !
TREG
(Target Transformed Regression for Accurate Tracking)
[논문리뷰] TREG
Target Transformed Regression for Accurate Tracking Yutao Cui Cheng Jiang Limin Wang* Gangshan Wu 0. Abstract 비디오에서 target의 (appearance variations, pose, view changes, geometric deformations)으로 인해 정확한 추적은 여전히 어려운
nozzi-study.tistory.com

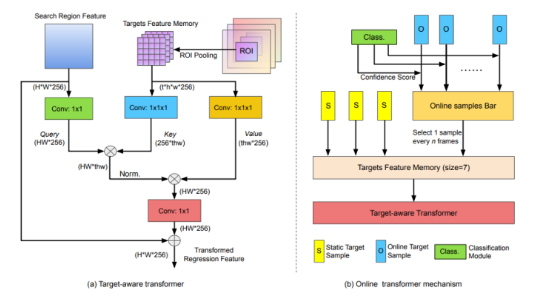
🎀 특징 및 요약
- DiMP[2]의 기존 온라인 분류 분기와 결합하여, 원칙적인 anchor-free tracking framework를 개발
💡 위의 분석에 따라, 본 논문에서는 context modeling에서 Transformer[32]의 성공에서 부분적으로 영감을 받아, TREG(Target Transformed Regression)라고 하는 transformer와 같은 설계를 가진 anchor-free 및 target-guided regression branch를 고안한다.
- 기본적으로, transformer의 ⅰ)cross-attention 매커니즘을 사용하여 target template과 search areas의 elements 사이의 모든 pairwise interaction을 명시적으로 모델링하여, 이러한 향상된 표현을 정밀한 boundary offset regression에 특히 적합하게 만든다.
- 구체적으로, target template에서 feature cells은 처음에 key and value로 인코딩된다.
- 그런 다음, search area의 각 위치에 대해 target template의 모든 key-value 쌍에 대한 feature를 querying 함으로써 시각적 표현을 향상시킨다.
- 이러한 검색된 target-aware 표현은 target template과 search regions의 모든 elements 사이의 local 및 dense matching 덕분에, target 관련 정보를 개선하고 object deformation을 어느 정도 처리할 수 있다.
- TREG의 효과를 더욱 향상시키기 위해, 추적된 객체의 변형을 유지하기 위해 ⅱ)online target template queue을 설정하고, 신뢰할 수 있는 target template을 적응적으로 선택하는 신뢰 기반 업데이터 전략을 설계한다. - anchor free와 관련
- 마지막으로 target transformed 표현 위에 ⅲ)피드포워드 네트워크를 배치하여 object boundary offset regression을 수행한다.
- 요약하자면,
- target transformed regression branch(TREG)를 고안하여, 정확한 anchor-free tracker를 제안한다.
target template and search area에서 elements 사이의 pair-wise relation을 모델링하는 이점은
TREG가 정확한 boundary 정보를 유지하고, objects variations을 효과적으로 처리할 수 있게 한다. - 신뢰 기반 template queue를 설정하여 simple online target update mechanism을 제시하며, 이를 통해 추적기는 시간에 따른 object의 외관 변화와 기하학적 변형에 유연하게 대처할 수 있다.
- target transformed regression branch(TREG)를 고안하여, 정확한 anchor-free tracker를 제안한다.
🎀 목적
- target information을 사용하기 위해, 기존의 anchor-free trackers는 target-guided attention 또는 depth-wise correlation을 사용하여 search frame 표현을 modulate(조절, 조정)하는데, 이는 정확한 회귀를 위한 target 정보가 불충분하고 object variation을 처리할 수 있는 유연성이 부족할 수 있다.
- 이러한 문제를 해결하고 우수한 성능을 얻기 위해 target transformed regression branch를 고안한다.
🎀 단점
SwinTrack
(A Simple and Strong Baseline for Transformer Tracking)
[논문리뷰] SwinTrack
SwinTrack: A Simple and Strong Baseline for Transformer Tracking Liting Lin1,2∗ Heng Fan3∗ Zhipeng Zhang4 Yong Xu1,2 Haibin Ling5 SwinTrack: A Simple and Strong Baseline for Transformer Tracking Recently Transformer has been largely explored in trackin
nozzi-study.tistory.com

🎀 특징 및 요약
🎀 목적
🎀 장점
🎀 단점
HiFT
(Hierarchical Feature Transformer for Aerial Tracking)
[논문리뷰] HiFT
HiFT : Hierarchical Feature Transformer for Aerial Tracking Ziang Cao† , Changhong Fu†,*, Junjie Ye† , Bowen Li† , and Yiming Li‡ HiFT: Hierarchical Feature Transformer for Aerial Tracking Most existing Siamese-based tracking methods execute the
nozzi-study.tistory.com


'Research' 카테고리의 다른 글
| [논문리뷰] ToMP (1) | 2023.01.27 |
|---|---|
| [Object Tracking] DCF-based Tracker (0) | 2023.01.26 |
| [논문리뷰] OSTrack (0) | 2023.01.12 |
| [논문리뷰] HiFT (0) | 2023.01.07 |
| [논문리뷰] AiATrack (1) | 2022.12.29 |
