Target Transformed Regression for Accurate Tracking
Yutao Cui Cheng Jiang Limin Wang* Gangshan Wu
1. Abstract
- 비디오에서 target의 (appearance variations, pose, view changes, geometric deformations)으로 인해 정확한 추적은 여전히 어려운 작업이다.
- 최근의 anchor-free trackers는 효율적인 regression mechanism을 제공하지만, 정확한 bounding box 추정은 하지 못한다.
- 이러한 문제를 해결하기 위해 본 논문은 정확한 anchor-free 추적을 위해 TREG라고 하는 Transformer-alike regression branch를 용도 변경한다.
- 본 논문 TREG의 핵심
- target template과 search region의 pair-wise relation을 모델링
- 정확한 bounding box regression을 위해 시각적 표현이 향상된 resulted target을 사용하는 것이다.
- 이 target contextualized(상황별) representation은 target relevant정보를 향상시켜 box boundaries를 정확하게 찾는 데 도움이 되며, local and dense matching mechanism으로 인해 어느 정도 object deformation을 처리할 수 있다.
- 또한 신뢰할만한 templates을 선택하기 위한, simple online template update mechanism을 고안
- 시간 내에 target의 appearance variations and geometric deformations에 대한 robustness를 높인다.
- VOT 2018, VOT 2019, OTB 100, GOT-10k, NFS, UAV123, LaSOT 및 TrackingNet을 포함한 시각적 추적 벤치마크에 대한 실험 결과는 TREG가 약 30FPS에서 LaSOT에서 0.640의 성공률을 달성한다는 것을 보여준다.
2. Introduction
1) VOT 간략한 설명
- Visual object tracking[1, 2, 9, 24]은 robotics, surveillance[38], human-computer interation[26]과 같은 광범위한 응용 프로그램을 가진 컴퓨터 비전에서는 중요하지만 어려운 작업이다.
- 초기 프레임의 target bounding box가 주어지면, 비디오 프레임에서 임의의 object의 상태를 추정하는 것을 목표로 한다.
- 최근 몇 년 동안 많은 진전이 있었지만[1, 2, 9, 24], target의 deformation, pose and viewpoint changes, 심지어 다른 objects에 의해 가려질 수 있다는 사실 때문에 accurate trackinig은 여전히 어렵다.
- 일반적으로 single object를 tracking하는 것은 classification and regression의 하위 작업으로 분해될 수 있는데, 이는 각각 target을 대략적으로 localize하고 정확한 bounding box를 회귀시키는 것이다.
2) box estimation에 대한 이전 연구
- accurate tracker를 구축하기 위해, regression branch design은 precise bounding box를 생성하는 역할을 하므로 매우 중요하다.
- box estimation에 대한 이전 연구는 두가지 유형으로 대략 분류할 수 있다.
(1) indirect bounding box estimation
-
- 초기 접근법[1]은 단순히 classification branch에 기반한 multi-scale searching 전략을 사용한다.
- 그런 다음, ATOM[9]의 방법은 최종 object box를 select하고 refine하기 위해, specializzed IoU prediction network를 제시한다.
(2) direct bounding box regression
-
- 기본 Siamese trackers[23, 24, 41]은 사전 정의된 anchor를 기반으로, bounding size를 회귀시키는 anchor-based mechanism에 의존한다.
- 최근에는, 일부 anchor-free tracker[5, 16, 39, 42]는 box size를 직접 회귀시킴으로써 설계의 단순성과 우수한 성능으로 인해 더 인기가 있다.
- 그러나 image object detection과는 달리, 이러한 anchor-free trackers는 추적 문제의 본질적인 illness으로 인해, object tracking을 위해서는 충분히 정확하고 강력하기 않기 때문에, 본 논문의 trakcer가 unseen deformations and variations에 잘 일반화될 것으로 기대한다.
3) 본 논문에서 해결해야 할 것
- 본 논문에서 목표는 object deformation, pose and view changes을 효과적으로 처리할 수 있는 맞춤형 regression branch를 제안하여, 보다 정확한 anchor-free tracker를 설계하는 것이다.
- 위의 분석을 바탕으로 정확한 anchor-free tracking의 핵심 문제는 target information을 regression branch에 통합하여, 정확한 boundary information을 유지하고 시간의 변화를 처리하는 방법이라고 주장한다.
- 기존의 anchor-free trackers[5, 16, 39, 42]는
- 단순히 target information을 융합하는 depth-wise correlation representation 사용
- visual representations을 modulate하는 target guided attention module을 사용한다.
- 이러한 기법은 target information integration을 위한 실현 가능한 solutions을 제공하지만, 정확한 regression을 위해 불충분한 target information이 포함되어 있을 지도 모르고, object variations을 다루기에 유연성이 부족할 수 있다.
- 이에 따라, 구체적으로 고려해야 할 두가지 중요한 요인을 파악한다.
- 첫째, 정확한 object boundaries를 생성하기 위해서는 충분한 target information을 regression branch에 유지해야 한다.
- 둘째, appearance variation, object deformation을 처리하기 위해, regression branch는 deformation과 함께 유연하고 시간이 지남에 따라 적응할 수 있을 것으로 기대된다.
4) 전체적인 아이디어 소개(중요!)
- 위의 분석에 따라, 본 논문에서는 context modeling에서 Transformer[32]의 성공에서 부분적으로 영감을 받아, TREG(Target Transformed Regression)라고 하는 transformer와 같은 설계를 가진 anchor-free 및 target-guided regression branch를 고안한다.
- 기본적으로, transformer의 ⅰ)cross-attention 매커니즘을 사용하여 target template과 search areas의 elements 사이의 모든 pairwise interaction을 명시적으로 모델링하여, 이러한 향상된 표현을 정밀한 boundary offset regression에 특히 적합하게 만든다.
- 구체적으로, target template에서 feature cells은 처음에 key and value로 인코딩된다.
- 그런 다음, search area의 각 위치에 대해 target template의 모든 key-value 쌍에 대한 feature를 querying 함으로써 시각적 표현을 향상시킨다.
- 이러한 검색된 target-aware 표현은 target template과 search regions의 모든 elements 사이의 local 및 dense matching 덕분에, target 관련 정보를 개선하고 object deformation을 어느 정도 처리할 수 있다.
- TREG의 효과를 더욱 향상시키기 위해, 추적된 객체의 변형을 유지하기 위해 ⅱ)online target template queue을 설정하고, 신뢰할 수 있는 target template을 적응적으로 선택하는 신뢰 기반 업데이터 전략을 설계한다. - anchor free와 관련
- 마지막으로 target transformed 표현 위에 ⅲ)피드포워드 네트워크를 배치하여 object boundary offset regression을 수행한다.
5) 정리
- DiMP[2]의 기존 온라인 분류 분기와 결합하여, 원칙적인 anchor-free tracking framework를 개발한다.
- 8개의 밴치마크에 대한 포괄적인 실험을 수행하여 이전 최첨단 방법에 대한 TREG의 우수한 성능을 입증한다.
- 이 작업의 기여는 세가지이다.
- target transformed regression branch(TREG)를 고안하여, 정확한 anchor-free tracker를 제안한다.
target template and search area에서 elements 사이의 pair-wise relation을 모델링하는 이점은
TREG가 정확한 boundary 정보를 유지하고, objects variations을 효과적으로 처리할 수 있게 한다.
-
- 신뢰 기반 template queue를 설정하여 simple online target update mechanism을 제시하며, 이를 통해 추적기는 시간에 따른 object의 외관 변화와 기하학적 변형에 유연하게 대처할 수 있다.
- TREG는 VOT2018, VOT2019, LaSOT, TrackingNet, OTB, GOT-10k, UAV123, NFS를 포함한 8개의 벤치마크 데이터 세트에서 인기 있는 최첨단 실시간(real-time) 추적기를 능가하며, 특히 LaSOT에서 0.640의 성공률을 달성하면서 약 30fps 속도로 실행된다.
3. Related Work
target regression의 측면에서 최근의 추적기를 간략하게 소개한다.
또한, tracking에 사용되는 transformer 매커니즘에 대해 논의한다.
3.1. Target regression for tracking
- Target regression : 정확한 target state를 추정하는 데 사용된다.
- 이전의 작업은 대략적으로 indirect target estimation과 direct bounding box regression의 두 가지 유형으로 분류할 수 있다.
1) Indirect target estimation
-
- 일부 CF-based trackers[8, 18, 28, 31] 및 SiamFC[1]은 대략적으로 target scale을 추정하기 위해 brutal multi-scale test를 사용했다.
- ATOM 및 DiMP는 specialized IoU prediction network를 사용하여 최종 object box를 선택하고 refine 한다.
2) Direct bounding box regression
-
- RPN-based trackers[24, 23, 43, 41, 40, 35]는 사전에 정의된 anchor box와 target location 사이의 위치 이동 및 크기 차이를 회귀시킨다.
- SATIN[15], CGACD[12]는 cross-correlation operation과 correlation-guided attention operation을 각각 사용하여 corners를 감지한다.
- SiamFC++[39]는 offset을 box corners로 직접 회귀시킨다.
- Anchor-free trakcers[5, 16, 42, 6]은 디자인이 단순하고 성능이 우수하기 때문에 점점 더 인기가 많아지고 있다.
- 그러나 target information을 사용하기 위해, 기존의 anchor-free trackers는 target-guided attention 또는 depth-wise correlation을 사용하여 search frame 표현을 modulate(조절, 조정)하는데, 이는 정확한 회귀를 위한 target 정보가 불충분하고 object variation을 처리할 수 있는 유연성이 부족할 수 있다.
- 이러한 문제를 해결하고 우수한 성능을 얻기 위해 target transformed regression branch를 고안한다.
3.2. Transformer mechanism in tracking
- 일반화된 transformer 매커니즘[32] : 전체의 input sequence의 정보를 집계하는 neural network layers의 그룹이다.
- Attention layers를 도입
- 시퀀스의 각 요소를 스캔하고
- 전체 시퀀스의 정보를 집계하여 업데이트한다.
- Attention layers를 도입
- visual tracking 영역에서 CSR-DFC[27]
- correlation filter learning을 제한하기 위해, object spatial attention map을 구성
- weighted sum correlation response maps의 채널 신뢰성 값을 계산한다.
- 그런 다음, RASNet[34]
- Siamese network에 공간 및 채널별 attention을 도입한다.
- CGCAD[12]
- corner detection을 위한 correlation-guided attention을 추가로 제안한다.
- 그러나 pixel-wise correlation-guided spatial attention은 target에 일부 background 부분이 있다는 사실을 간과하여, object region 외부에서 높은 attention weights를 초래할 수 있다.
- 결과적으로 그들은 문제를 완화하기 위해 하나의 RoI를 추정한 다음, corners를 감지하기 위한 복잡한 2단계 구조를 채택한다.
- 그것들에 비해 본 논문의 target-aware transformer는 regression 표현을 향상시키기 위해 충분한 target 정보를 가지고 있으며, 간단한 구조 덕분에 online regression에 쉽게 배치할 수 있다.
4. Proposed Method
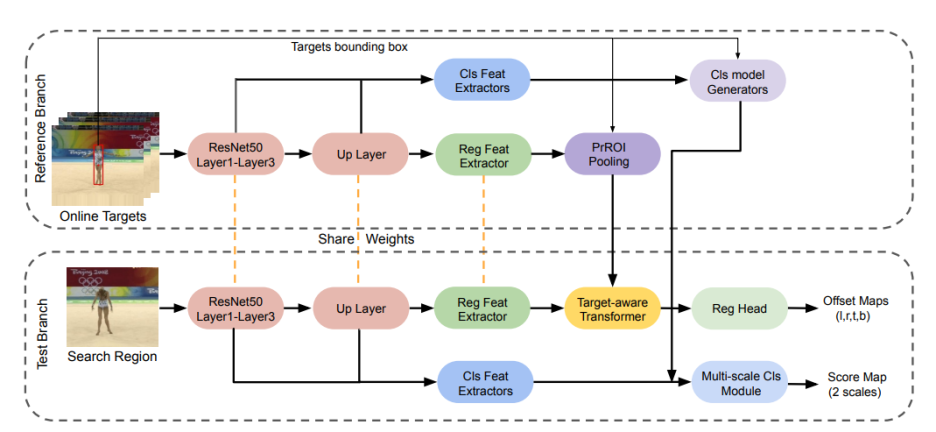
1) 전체적인 내용(Idea)
- 정확한 anchor-free 추적을 위한, 온라인 업데이트 메커니즘을 갖춘 target transformed regression branch를 개발한다.
- online target transformed regression component는 기본적으로 다음 지침을 준수하여 고안되었다.
- a fully target integration module
- 정확한 객체 경계 생성을 위해, 충분한 target 정보를 보유할 수 있는, 고품질 시각적 표현을 제공
- pixel-wise context modeling
- target-relevant features를 향상시키고, object deformation에 대처하기 위해
- efficient online mechanism
- 연속적인 순서로 외관 변화를 처리
- a fully target integration module
2) 전반적인 순서
- Context modeling의 transformer와, 컴퓨터 비전의 variants[32, 36]에서 영감을 받아, anchor-free regression을 위한 transformer와 유사한 구조를 고안한다.
- query element와 key elements의 집합이 주어지면, trnasformer function은 query-key pairs의 호환성을 측정하는 attentive weights에 기반하여, query feature을 transform시키기 위해 key contents를 적응적으로 집계한다.
- 이러한 기술적 관점에 따라, target-aware transformer는 target appearance를 regression features에 통합하도록 설계되었다.
- 백본 및 ROI pooling layers에 의해 추출된 target template의 feature cells.
- key and value elements에 의해 인코딩된다.
- 그런 다음, search region의 각각의 위치에 대해, 모든 key-value 쌍에 걸쳐, feature를 querying
- 시각적 표현을 향상시킨다.
- 그런 다음, 검색된 표현이 원래 feature에 융합
- 회귀를 위한 풍부한 target-aware 정보를 얻을 수 있다.
- target template과 search regions의 모든 elements 사이의 local and dense matching
- regression에 대한 high-quality 표현을 생성하기 위한 충분한 target 정보를 보존
- object 변형도 어느 정도 처리할 수 있다.
- online target template queue를 설정
- 추적된 object의 변형을 유지
- 구성요소
- threee static targets(주어진 템플릿에 의해 augmented)
- reliable online targets(분류 신뢰도에 따라 적응적으로 선택됨)
- 마지막으로, 피드포워크 네트워크
- target transformed 표현 위에 배치되어, object boundary offset 회귀를 직접 수행한다.
3) 모델 간단히 설명
- 제안된 목표 변환 회귀 분기를 기반으로 온라인 분류 분기를 결합하여 효율적이고 원칙적인 앵커 프리 트래커(TREG)를 구축한다. (그림2)
- 전반적인 구성 요소
- 전체 프레임워크는 분류 및 회귀 분기에 대한 특징을 추출하기 위한 공통 백본
- 대상 중심을 localize하기 위한 분류 분기
- 정확한 대상 상태를 추정하기 위한 회귀 분기로 구성된다.
- Multi-scale 온라인 분류 구성 요소를 사용
- FCOT[6]와 유사하게 사용하는데, 이것은 우리는 강력한 대상 센터 위치를 추정하기 위해, DiMP[2]에서 차별적 모델 생성기가 제안된 것
- 온라인 target queue에서 대상 센터 위치와 템플릿이 주어지면, 대상 인식 변압기는 향상된 시각적 기능을 생성하며, 이는 오프셋을 객체 경계로 직접 회귀시키는 데 사용된다.
4.1. Target transformed regression
1) 위의 내용들을 간략히 정리
- 일반적으로 anchor-free regression
- 피드포워드 네트워크를 사용하여
- object center에 대한 box boundary의 기하학적 offsets을 예측하기 위해 appearance 표현만을 기반으로 한다.
- 목표
- appearance 정보와 기하학적 구조 사이의 격차를 메우기 위해, 본 논문에서는 보다 상세한 구조 정보(ex. object boundary)를 시각적 표현에 통합하여 기하학적 구조 예측의 어려움을 완화하기를 희망한다.
- 즉, 특정 anchor가 없는 object tracking과 관련하여, 보다 상세한 target 정보를 활용하여 object relevant area를 향상하는 동시에 배경에서 산만함을 억제하는 것을 목표로 한다.
- correlation의 문제점
- depth-wise correlation[5, 39, 42, 16]
- 전체 target이 correlation filter로 제공되기 때문에 object deformation과 마주하는 target의 눈에 띄지 않는 boundary를 갖는 유사도 맵을 산출한다.
- pixel-wise correlation-based attention[12]
- 불충분한 target 정보를 유지하기 때문에 다른 문제를 부과한다.
- target에 background 부분이 존재할 때, target 외부 영역이 높은 attention weight로 할당될 수 있다.
- depth-wise correlation[5, 39, 42, 16]
- 이러한 단점을 극복하기 위해, target and search area 사이의 모든 pair-wise correlation를 더 잘 활용하기로 선택하고, 이러한 풍부하고 고차적인 features를 활용하여 충분한 target-related 정보를 유지하고 추적하는 동안 object variation 문제를 처리하는 것을 목표로 한다.
2) Target-aware transformer
2-1) 수식 설명
- 위의 분석에 요약되었듯이, 본 논문의 target transformed regression은 transformer 아키텍쳐[32]에서 영감을 받아 재목적화한다.
- 기본적으로 search area를 쿼리로 사용하여 target 정보로 표현력을 향상시킨다.
- 구체적으로, target hidden 표현은 픽셀 단위로 key and value elements로 인코딩되어,
- search region feature의 위치인 qeury에 대한 weighted aggregation reponse를 제공한다.
- 본 논문에서는 target-aware feature transformation을 다음과 같이 정의한다.
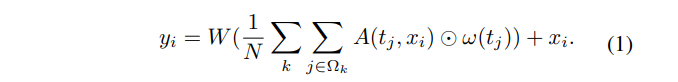
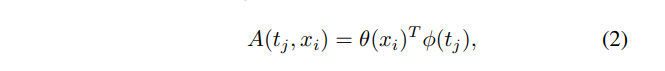
- i : search regioin의 위치를 x_i로 인덱싱한다.
- j : feature representation t_j가 있는 target template에서 가능한 모든 위치를 열거하는 인덱스
- k : target queue에서 template을 인덱싱한다.
- Ω_k : query에 대한 targe template의 feature cell을 지정한다.
- w : value element로 제공되는 위치 j에서 target signal의 표현을 계산한다.
- A(t_j, x_i) : t_j and x_i 사이의 관계를 나타낸다.
- θ : query element로 x_i를 인코딩
- φ : key element로 t_j를 인코딩
- Target-aware information aggregation : weighted sum으로 이루어진다.
- 그런 다음, 가중 합계를 1/N으로 조정하여 정규화를 수행한다.
- N : t(템플릿의 수) x h(템플릿의 크기) x w(템플릿의 크기)
- 정규화 계수 1/(t x h x w)는 [36, 32]에서와 같이 Softmax 함수로 대체할 수 없다.
- 배경에서의 일부 위치와 search region의 산만함은 target과의 의존성이 낮을 것으로 예상
- 반면, softmax 함수는 쿼리와 모든 키 사이의 attention weights의 합이 항상 1이기 때문에 이러한 노이즈 영향을 증폭시키기 때문
- W : queried feature을 x_i와 같은 모양으로 만드는 feature transformdmf skxksosek.
- y_i : 원래의 features와 검색된 표현의 단순한 평균을 가진 target transformed representation
2-2) Target-aware transformer 아키텍쳐 설명
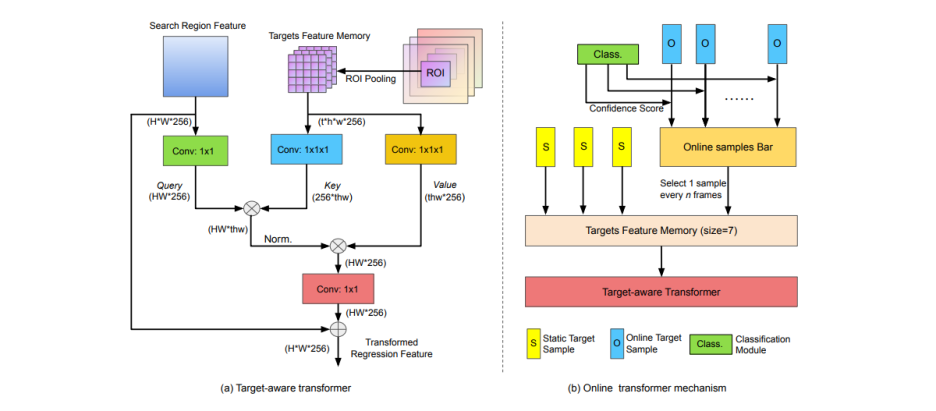
- 그림 3과 같이, target-aware transformer의 입력
- search region feature : 88x88(spatial size)
- ROI-pooled target feature : 5x5(target size)
- 함수 φ and w : 각각 커널 크기가 1x1x1인 3D 컨볼루션 레이어로 구현
- 3.2에 설명된 대로 online 3D targets menory가 유지되기 때문이다.
- 마찬가지로 함수 θ and W : 커널 크기가 1x1인 2D 컨볼루션 레이어
- A target-aware transformer operation은 유연한 building block이며, 현재의 anchor-free trackers에 쉽게 삽입될 수 있다.
- block에서 offline으로 훈련될 커널 크기가 1인 컨볼루션 레이어는 4개뿐이다.
- 또한 온라인 업데이터를 위해 쉽게 배포될 수 있는 다양한 크기의 target queue를 유지할 수 있다.
3) Discussion with other anchor-free regression
3-1)
target-aware transformer의 통찰력을 더 잘 설명하기 위해, 이전의 anchor-free trackers의 regression 구성요소와 비교한다.
일반적으로 anchor-free regression에서 search region featrue에 target 정보를 통합하는 두가지 주요 방법이 있다.
첫째, [39, 16, 5, 42] 대부분은 전체 template을 기반으로 유사도 맵을 생성하기 위해 depth-wise correlation을 사용한다.
correlation filter는 단순히 target의 global 정보를 보유하기 때문에, 변형이나 이와 유사한 복잡한 상황에 직면했을 때 object booundary를 정확하게 반영하기 어렵다.
둘째, CGACD[12]는 corner를 감지하기 위해 복잡한 correlation-guided attention을 가져오는데, 이것은 다른 한계를 부과한다.
pixel-wise correlation은 target-aware spatial attention을 생성하기 위한 주요 작업이다.
그러나 target에 일부 배경 부분이 있어, target region 외부에서 높은 attention 가중치를 초래할 수 있다는 사실을 간과한다.
결과적으로 그들은 이 문제를 완화하기 위해 target을 포함할 것으로 예상되는 하나의 RoI를 추정한 다음, corner를 감지하기 위한 복잡한 2단계 구조를 채택한다.
3-2)
대조적으로 본 논문의 target-aware transformer는 target template and search area의 elements 사이의 모든 pair-wise interactions을 명시적으로 모델링하고, 검색된 feature 표현을 사용하여 원래의 특징을 향상시킨다.
이러한 독특한 설계는 본 논문의 target transformed 표현을 이전 방법보다 더 상세한 target-relevant 정보를 얻고, local and dense matching 매커니즘으로 인한 물체의 외관 변화 및 변형을 잘 처리하도록 만든다.
exploration 연구는 본 논문의 target transformed regression이 4.1절에서 논의한 바와 같이 더 정확한 추적 결과를 산출할 수 있음을 보여준다.
4.2. Online template update
연속적인 sequence의 target variatioins에 대처하기 위해, 그림 3(b)에서 시각화된 대로 regression을 위한 online template updata 매커니즘을 제시한다.
온라인 체계와 함께 발생하는 고유한 문제는 추적된 objects가 부정확할 수 있다는 것이다.
따라서 추적기는 혼란스럽고 표류하는 경향이 있다.
정확한 회귀는 online targets and static targets 사이의 균형을 이루는 것이 중요하다.
따라서 3개의 static targets and 4개의 online targets으로 구성된 online targets template queue이 유지된다.
static targets : 주어진 template에 대한 데이터 aumentation을 수행하여 획득된다.
online targets memory : n 프레임마다 업데이터된다.
여기서 n은 업데이트 간격이다.
추적된 targets은 불안정하기 때문에 신뢰할 수 있는 target template을 적응적으로 선택하기 위한 신뢰 기반 업데이터 전략을 설계하는 바이다.
object가 samples bar의 online targets 사이에서 최대 신뢰도로 예측되면, 해당 template이 target queue에 추가된다.
실험 결과는 4.1절의 online template update 매커니즘의 효과를 입증한다.
4.3. Implementation details
1) Framework
[2:DiMP]의 아키텍쳐를 따라, 본 논문에서는 common feature를 추출하기 위해 ResNet-50[17] 백본을 사용한다.
그런 다음 2개의 콘볼루션 레이어와 2개의 up-sampling layer로 구성된 UP 레이어를 사용하여 high-resolution feature를 생성한다.
그런 다음 Classification head와 regression head는 분류 및 회귀 task를 개별적으로 처리할 수 있는 task-specific feature를 추출한다.
분류 헤드와 회귀 헤드의 구성 : convolution layer and 2 deformable concolution layers[7]
[6]과 유사한 multi-scale classification branch를 사용하여 [2]에서 제안된 discriminative model을 학습한다.
먼저, Low-resolution score map과 high-resolution score map은 별도의 온라인 분류기에 의해 생성된다.
그런 다음 이 두 맵을 융합하여 강력하고 정확한 target center를 예측한다.
훈련 하는 동안, classification 목표는 ground-truth target center를 중심으로 한 Gaussian function map.
Regression branch
구성 : 제시된 target-aware transformer와 2개의 컨볼루션 레이어와 deformable 컨볼루션 레이어를 포함하는 피드포워드 네트워크
추정 : point에서 target boundary까지의 offset을 추정한다.
오프라인 훈련 과정에서 반경 2의 영역인 target center 부근의 위치에 대한 regression을 수행한다.
2) Offline training
몇몇 인기있는 추적기들[2, 6, 9, 11]와 유사하게, LaSOT[13], TrackingNet[30], GOT-10k[19] 및 COCO[25]의 training splits를 사용한다.
8개의 Nvidia Tesla V100 GPUs에서 총 100시간의 훈련 시간을 부여하여 에폭 당 40000개의 비디오를 샘플링하여 50 에포크 동안 모델을 훈련시킨다.
전체 네트워크는 80개의 미니 배치 크기로 end-to-end로 훈련된다.
25와 35의 에포크에서 0.2의 learning rate decay를 가진 ADAM[20]을 사용한다.
classification training loss 설정은 DiMP[2]와 동일하다.
regression의 경우, IoU 손실을 사용하여 손실 가중치는 1로 설정된다.
3) Online training
translation, rotation, blurring을 사용하여 첫번째 프레임에서 data augmentation을 수행하여,
온라인 분류를 위한 총 15개의 initial online training samples를 산출한다.
그리고 3개의 샘플을 online target template queue를 위한 static targets로 설정한다.
추정 과정 동안, 신뢰할 수 있는 샘플을 선택하기 위해 설계된 신뢰 기반 업데이터 전략을 사용한다.
가장 오래된 샘플을 폐기하여 최대 queue size를 7로 보장한다.
온라인 분류는 [6]과 같이 수행된다.
5. Experiments
추적 접근 방식은 PyTorch를 기반으로 Python에서 구현된다.
Inference를 위해, 우리의 추적기를 single Nvidia RTX 2080Ti GPU에서 테스트하여, 약 30fps의 추적 속도를 달성한다.
5.1. Exploration study
본 연구에서 제안된 transformer에 대한 target transformed regression 및 online template updating mechanism의 영향을 분석하는 실험을 설명한다.
실험은 ATOM[9]에서와 같이, UAS123[29] 및 NFS[14] 데이터 세트에 대해 수행된다.
총 233개의 challenging videos가 있다.
area-under-the-curve(AUC) 점수와 precision score(Precision)라는 두가지 메트릭을 보고한다.
공정한 비교를 위해 다음 실험은 모두 동일한 교육 환경에서 수행된다.
1) Target-aware transformer for regression
주요 기여는 제안된 target transformed regression branch이다.
그 효과를 평가하기 위해, anchor-free 추적을 위한 다음과 같은 유사한 방법과 비교한다.
공정한 비교를 위해 , classification branch 및 feed-forward network를 포함한 다른 구성 요소들이 동일한 반면, target aware transformer 를 다음 모듈로 대체한다.
그리고 TREG는 온라인 샘플 없이 주어진 target을 template으로 활용한다.
[Baseline]
target-aware transformer를 제거한 baseline approach와 비교한다.
표1에서 보이는 바와 같이 Precision에서 3.5%, AUC에서 4.4%의 성능 저하가 나타나 target 정보를 regression 표현에 통합하는 것이 매우 중요함을 알 수 있다.
[DW-Corr]
그런 다음, [5, 16, 39, 42]에서 일반적으로 사용되는 depth-wise correlation 기반 regression 방법과 비교한다.
정확한 회귀를 위해 target deformation을 처리할 수 없기 때문에 성능은 본 논문의 방법에 비해 떨어진다.
[PCorr-Att]
[12]에서 제안된 pixel-wise correlation-guided attention 모듈과 비교한다.
이는 target-aware transformer와 관련성이 높기 때문이다.
본 논문의 방법보다 성능이 떨어지는데, 이는 regression 표현을 위해 충분한 target 정보를 유지하는 것이,
background 또는 distractors의 간섭을 제거하는 데 필수적이라는 것을 보여준다.
그림 4에서, 제안된 방법이 다른 방법보다 대상의 경계를 더 잘 나타낸다는 것을 설명하기 위해,
regression feature에 대한 직관적인 시각화 샘플을 추가로 제공한다.
물체는 sequence에서 변화하지만, target-aware transformer를 통해, 머리와 발을 포함한 다이버의 boundary가 강화되는 것을 볼 수 있다.
2) Target-aware transformer for classification
target-aware transformer for classification branch의 appliance(기기)를 추가로 분석하며,
high-resolution classification module을 제안된 transformer-alike 구조로 대체한다.

TAT-Cls의 성능이 TREG 만큼 좋지 않다는 것을 표1에서 볼 수 있다.
구체적으로, pixel-to-pixel matching 방법은 그림5에서 도출할 수 있는 targets의 전반적인 정보를 간과하는 경향이 있기 때문에, 유사한 대상을 구별하는 데 적합하지 않다.
결과적으로 target-aware transformer는 본 논문의 설계에서 classification에 사용되지 않는다 !
3) Online template update
Online transformer 매커니즘이 회귀에 미치는 영향을 조사한다.
조사 결과는 표2와 같다.
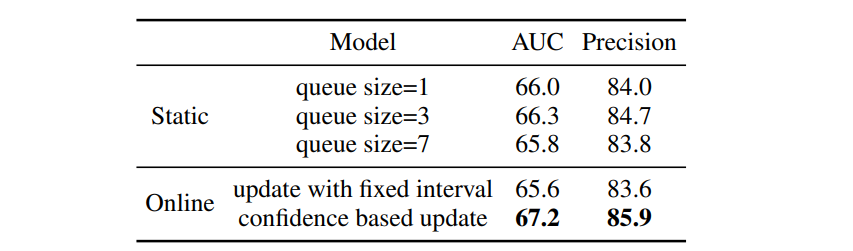
본 논문의 설계에서 online target queue는 static targets memory + online updating targets memory로 구성
static targets memory의 크기가 약간의 영향을 미친다는 것을 도출할 수 있다.
static target만을 사용하는 것과 비교하여, online target template queue를 유지하는 것은 AUC를 0.9%, Precision을 1.2% 향상시킨다.
그것은 online regression mechanism의 효과를 보여준다.
또한 online target을 신뢰할 수 없기 때문에, 신뢰 기반 업데이터 전략이 없으면 성능이 약간 떨어진다는 것을 관찰하여 이 계획의 효과를 입증한다.
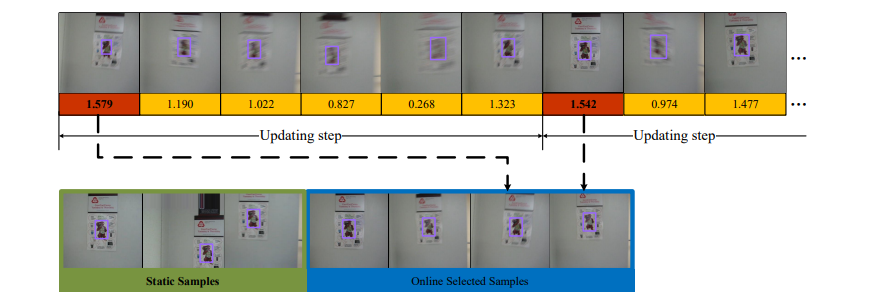
또한 그림 6에서 online dence queue를 시각화한다.
높은 신뢰도 점수는 일반적으로 high-quality 샘플에 해당한다는 것을 도출할 수 있으며,
이는 online samples selection 전략이 유용하다는 것을 증명한다.
5.2. Comparision with the state-of-the-are
VOT2018[22], VOT2019[21], LaSOT[13], TrackingNet[30], UAV123[29], GOT10k[19], OTB100[37], NFS[14]를 포함하는 8개의 tracking 벤치마크에서 TREG를 테스트하고, 최신 추적기들과 비교한다.
1) OTB-100
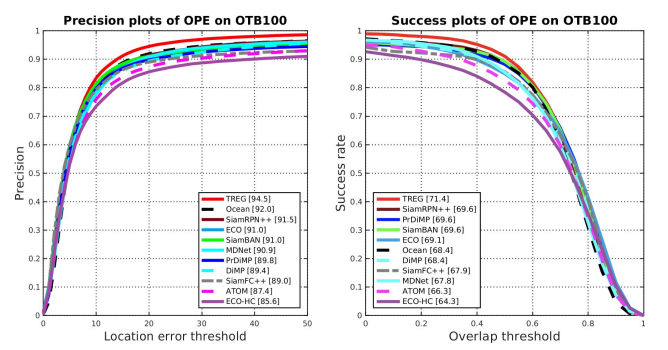
- OTB100[37]은 흔히 사용되는 벤치마크인데, 이 벤치마크는 Precision과 AUC score를 평가한다.
- 그림 7은 OTB-100 벤치마크의 두가지 메트릭에 대한 TREG의 평가 결과를 보여준다.
- AUC 점수 및 Precision 점수에서 각각 71.4%, 94.5%를 달성한 추적기는 다른 추적기와 비교하여 최첨단 수준에 도달한다.
2) LaSOT
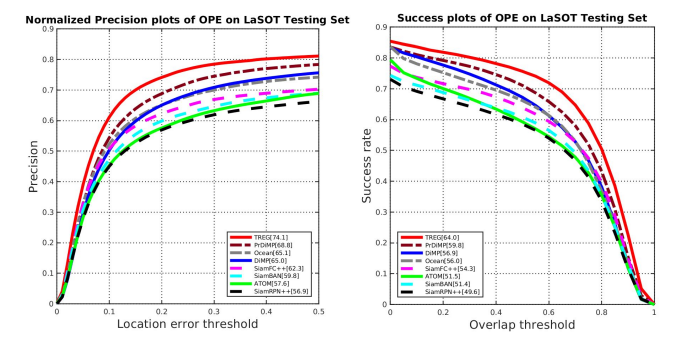
- LaSOT[13]의 테스트 세트에는 280개의 비디오가 있다.
- 테스트 세트에서 TREG를 평가하여 long-term 능력을 입증한다.
- 그림 8은 TREG가 큰 margin으로 다른 real-time trackers를 능가한다는 것을 보여준다.
- 구체적으로 AUC 64.0%, 정밀도 74.1%를 받아 1위의 성과를 달성한다.
- 놀라운 성능은 [TREG가 long-term tracking에 적응할 뿐만 아니라, online targets regression의 precision을 유지한다는 것]을 시사한다.
3) VOT-2018
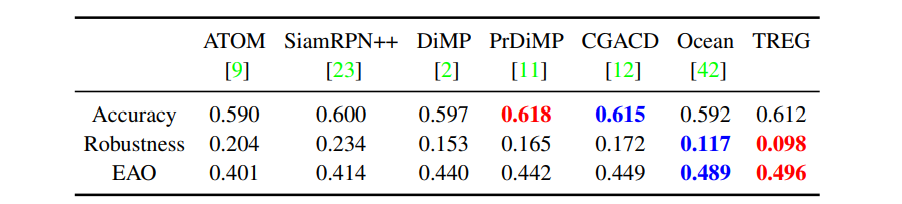
- TREG는 SOTA 추적기와 비교하여 60개의 비디오로 구성된 VOT2018[22] 데이터 세트에서 테스트된다.
- 표3에 나타난 바와 같이, TREG는 0.496의 EAO, 0.098의 Robustness를 달성하여 모든 최첨단 추적기를 능가한다.
- 향상된 정확도는 TREG가 정확한 경계 상자를 생성할 수 있음을 시사한다.
4) VOT-2019
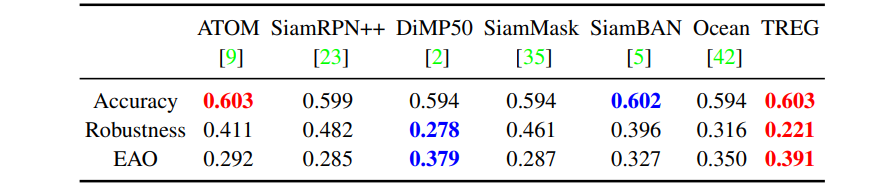
TREG는 SOTA 추적기와 비교하여 60개의 비디오로 구성된 VOT2019[21] 데이터 세트에서 테스트된다.
표4에 나타난 바와 같이, TREG는 EAO(0.391), Robustness(0.221), Accuracy(0.603)을 달성하여 모든 최첨단 추적기를 능가한다.
TREG가 정확한 경계 상자를 생성할 수 있음을 시사한다.
5) TrackingNet
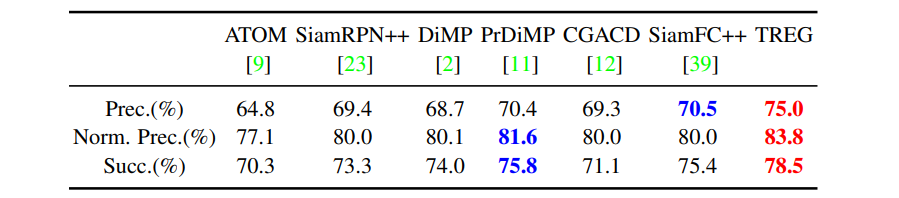
- TrackingNet[30]은 1400만개 이상의 dense bounding box annotations이 포함된 30k개 이상의 비디오를 제공한다.
- 그 비디오들은 유튜브에서 샘플링되어 실제의 target categories와 장면들을 다룬다.
- 테스트 세트에서 TREG를 검증하고, 세가지 메트릭 모두에서 두드러진 개선을 달성한다.
- TREG는 대규모 벤치마크에서 추적 성능을 향상시키는 것으로 입증되었다.
6) GOT10k
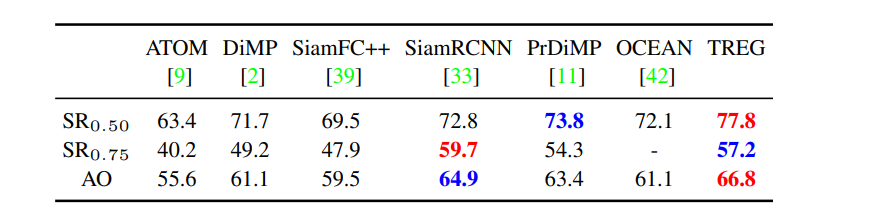
- GOT10k[19]는 10000개 이상의 비디오 세그먼트를 가진 대규모 데이터 세트
- 테스트 세트를 위한 180개의 세그먼트를 가지고 있다.
- moving objects와 motion patterns의 일반적인 클래스를 제외하고, train and test set에서 object class들이 겹치는 것은 없다.
- TREG는 test split에서 최첨단 성능을 얻는다.
7) UAV123

- UAV123[29]는 123개의 시퀀스(평균 시퀀스 길이가 915 프레임)들을 포함하는 대규모 데이터 세트이며, 저고도 UAVs로부터 캡쳐된다.
- 표7은 UAV123 데이터 세트에 대한 결과를 보여준다.
- TREG는 정밀도에서 이전에 가장 잘 보고된 결과를 능가한다.
- AUC 점수의 경우, TREG는 PrDiMP에 가까운 66.9%를 달성한다.
8) NFS

- NFS 데이터세트[14]는 실제 시나리오로부터 100개의 비디오에서 380K개의 프레임이 포함되어 있다.
- 이 데이터 세트의 30FPS 버전에서 TREG를 평가한다.
- 표8에 나타난 바와 같이, TREG는 이전의 모든 접근 방식을 상당한 차이로 능가한다.
- 결과는 정확한 회귀에 대한 TREG의 효과를 보여준다.
6. Conclusions
- Target-aware transformer(TREG)를 제안
- regression component를 detection에서 tracking으로 전송하기 위해
- regression을 위한 target integration의 과정
- target features에 의해 안내되는 pixel-wise feature transformation으로 공식화
- 효율적인 온라인 회귀 메커니즘을 탐구
- 업데이트 대상 메모리를 유지하고, 신뢰할 수 있는 샘플들을 선택
- 본 논문의 접근 방식은 산만한 객체에 대해 강력하면서도, 정확한 목표 추정을 제공했으며, 8개의 데이터 세트에서 이전 방법을 능가했다.
'Research' 카테고리의 다른 글
| [논문리뷰] OSTrack (0) | 2023.01.12 |
|---|---|
| [논문리뷰] HiFT (0) | 2023.01.07 |
| [논문리뷰] AiATrack (1) | 2022.12.29 |
| [논문리뷰] SwinTrack (1) | 2022.12.20 |
| [논문리뷰] SparseTT (0) | 2022.12.19 |
